
- 東京科学大学 工学院情報通信系 准教授
- 専門: 量子誤り訂正、符号理論、情報理論
量子LDPC符号では、X/Z検査行列の直交性制約がタナーグラフに短いサイクルを生み、 最小距離やデコーディング性能に本質的な制約(orthogonality barrier)を与えることが知られています。 この壁は、古典LDPC符号で有効だった次数分布設計、ガース制御、短サイクル除去、 density evolution によるBPしきい値最適化といった設計思想を、量子LDPC符号へ自由に持ち込めないという障害でもあります。 本研究では、置換行列の可換性を制御して直交性条件を「構成上必要な部分」に限定し、 正則構造を保ちながら大きなガースを持つCSS量子LDPC符号を明示的に構成します。 これにより、直交性を満たしつつ、古典LDPC符号で培われた設計自由度を量子LDPC符号の構成に取り込むことを目指しています。
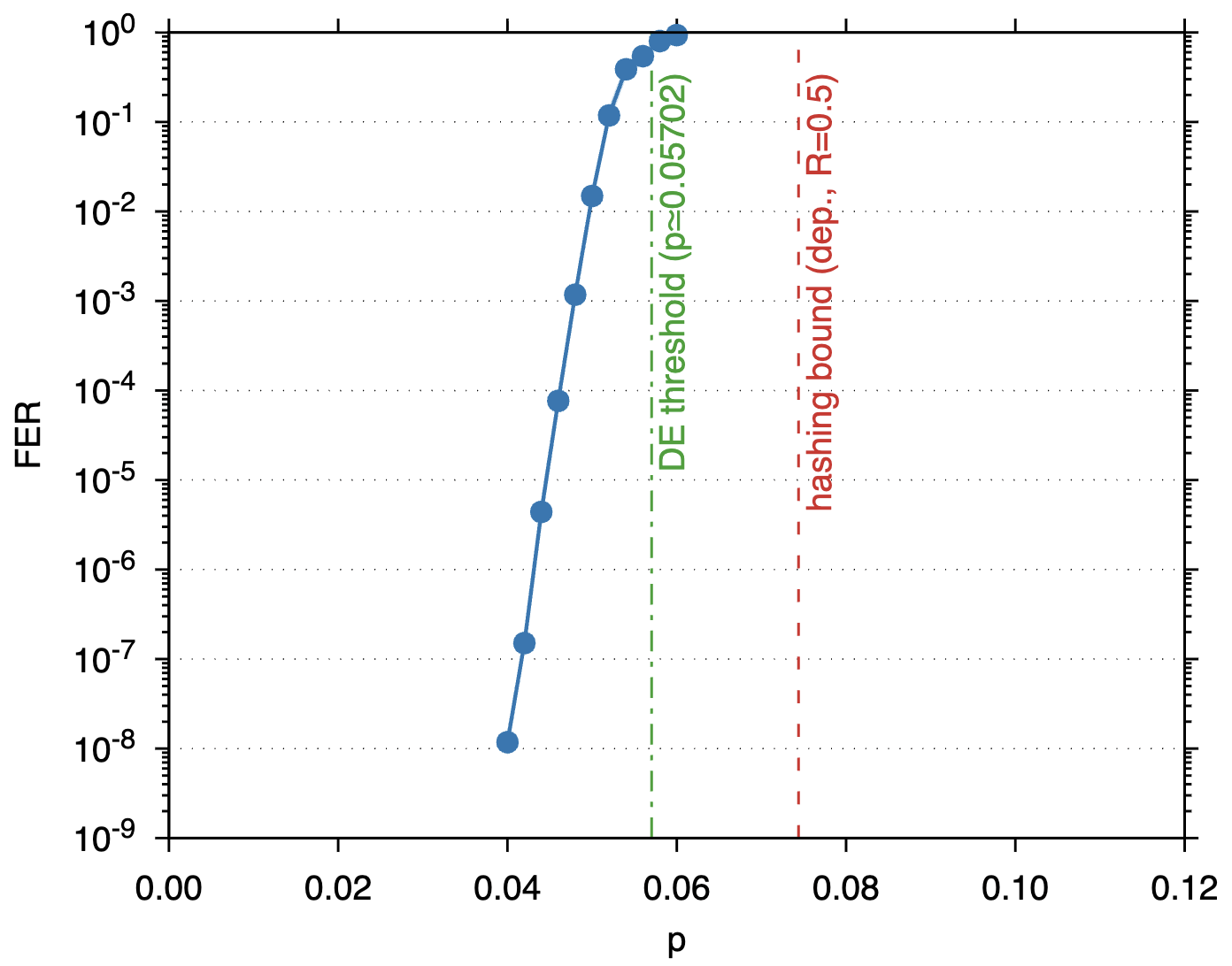
具体例として、ガース8の(3,12)-正則 [[9216, 4612, ≤48]] CSS量子LDPC符号を構成し、 BP復号と低計算量の後処理を組み合わせて脱偏極チャネル上で性能評価を行いました。 p=4% において FER=10-8 を達成し、密度発展によるしきい値は p=0.05702 と見積もられています。
Breaking the Orthogonality Barrier in Quantum LDPC Codes (arXiv:2601.08824)
関連する正則CSS LDPC基底符号の有限体二分岐構成と、\((3,10)\)-正則 \([[10240,4108,10\le d\le32]]\) 符号を与える 64-fold CPM lift の構成情報は arXiv:2605.23894 の補足ページ にまとめています。
また、アフィン剰余類構造に基づく \((3,8)\)-正則CSS基底符号と、 \([[16384,4142,\le40]]\) 符号を与える P=32 CPM lift の構成情報は arXiv:2604.20838 の補足ページ にまとめています。
さらに、\(\mathbb F_{19}\) 上の二分岐基底と P=101 CPM lift から得られる レート2/3、girth 8、\((3,18)\)-正則CSS量子LDPC符号 \([[34542,23032,d\le310]]\) の構成情報は arXiv:2606.27130 の補足ページ にまとめています。リフト係数、展開後の検査行列、forbidden support、 および距離上界に関する検証データを掲載しています。
ペア分割によるCPMベースCSS量子LDPC符号構成 arXiv:2607.14091 の構成データ、検証記録、CPMインスタンスは 特設ページ にまとめています。
BP復号後の後処理アルゴリズム(局所修復、OSD-lite、K-OSD、全変数syndrome solve)の整理は BP後処理アルゴリズムのメモ にまとめています(English version)。
・Reed-Solomon符号
link
・最小ヒープ
link
・ハフマン符号
link
・語頭符号
link
・算術符号
link
・LZ78符号
link
・\(\mathbb{Z}_n^\times\)が巡回群となる\(n\)
link
実用的な量子計算を実現するためには、多数の信頼できる論理量子ビットを構築することが不可欠です。 しかし現在の量子コンピュータの規模では、物理量子ビットが数千個あっても、論理量子ビットは数十個程度しか得られません。 この制約は、デバイス実装や安定性といった工学的要因による部分もありますが、 量子誤り訂正の符号理論を理想化して考えても、符号設計そのものに根本的な課題が残されています。
低計算量のビリーフプロパゲーション (BP) 復号と組み合わせた量子 LDPC (Low-Density Parity-Check) 符号は、 有望なアプローチとして長らく期待されてきました。 しかし、以下のような問題が依然として存在しています:
現時点では、これらすべての課題を同時に克服した量子誤り訂正方式は存在していません。
一方で古典誤り訂正の分野はすでに成熟しています。 例えば移動通信では LDPC 符号が 5G 規格に採用され、通信インフラの中核を担っています。 またパソコン上でも、符号長 \(10^7\) ビット規模の大規模シミュレーションが可能です。 このように古典通信では超大規模符号の実用展開が達成されていますが、 量子誤り訂正符号は依然として同等の水準には到達していません。
この状況に対応するため、私たちの研究グループは量子 LDPC 符号を用いた誤り訂正、 特にスパースな二元または非二元行列に基づく CSS (Calderbank–Shor–Steane) 符号の構成と復号に取り組んでいます。 実用的な復号アルゴリズムのもとでハッシング限界に近づく量子符号の設計を目指しています。
大きな成果のひとつは、置換行列から構成した明示的な量子 LDPC 符号の開発です。 これらは脱分極チャネル上で優れた誤り訂正性能を示し、 タナーグラフ内の短い閉路を避けることでエラーフロア現象を抑制しています。
また、量子雑音モデルに特有の縮退性を考慮した復号アルゴリズムも開発しています。 これにはシンドロームに基づく復号法や、ガロア体上に適応したビリーフプロパゲーション法が含まれます。 最近の結果では、双対符号と適切な後処理を組み合わせることで、復号成功率が大きく向上することが示されています。
これらの研究を通じて、ハッシング限界に近い性能の達成、低レート領域におけるエラーフロアの低減、 大きな巡回長を持つ符号の構成、鋭い誤り率遷移を示す二元 LDPC 符号の発見などを実現してきました。 本研究は、スケーラブルで耐故障性のある量子通信・量子計算の実現という長期的目標に貢献しています。
密度発展法は、有限長の量子 LDPC 符号を実際に構成する前に、 「X/Z の復号グラフがその次数分布を持つランダム LDPC アンサンブルのように振る舞うなら、 どの次数分布で BP 復号しきい値が良さそうか」を調べるための設計指針になります。 ここで示す計算は、直交制約を満たす CSS 符号アンサンブルの漸近解析ではありません。 明示的な CSS 構成で実現を試みる価値のある次数分布を探すための、符号理論的なベンチマークです。
density evolution とは、有限長の特定の Tanner graph を直接シミュレーションするのではなく、 符号長が無限大で局所近傍が木のように見えるという近似のもとで、 BP メッセージの確率分布が反復ごとにどう変化するかを追う解析手法です。 有限長グラフでは閉路や個別の構造が復号に影響しますが、density evolution ではそれらを平均化し、 通信路の誤り率、変数ノード次数分布、検査ノード次数分布から決まる典型的なメッセージ更新だけを扱います。 そのため、これは「その次数分布なら無限長・木近似の BP がどこまで成功しそうか」を測るベンチマークであり、 構成済み有限長 CSS 符号の性能証明そのものではありません。
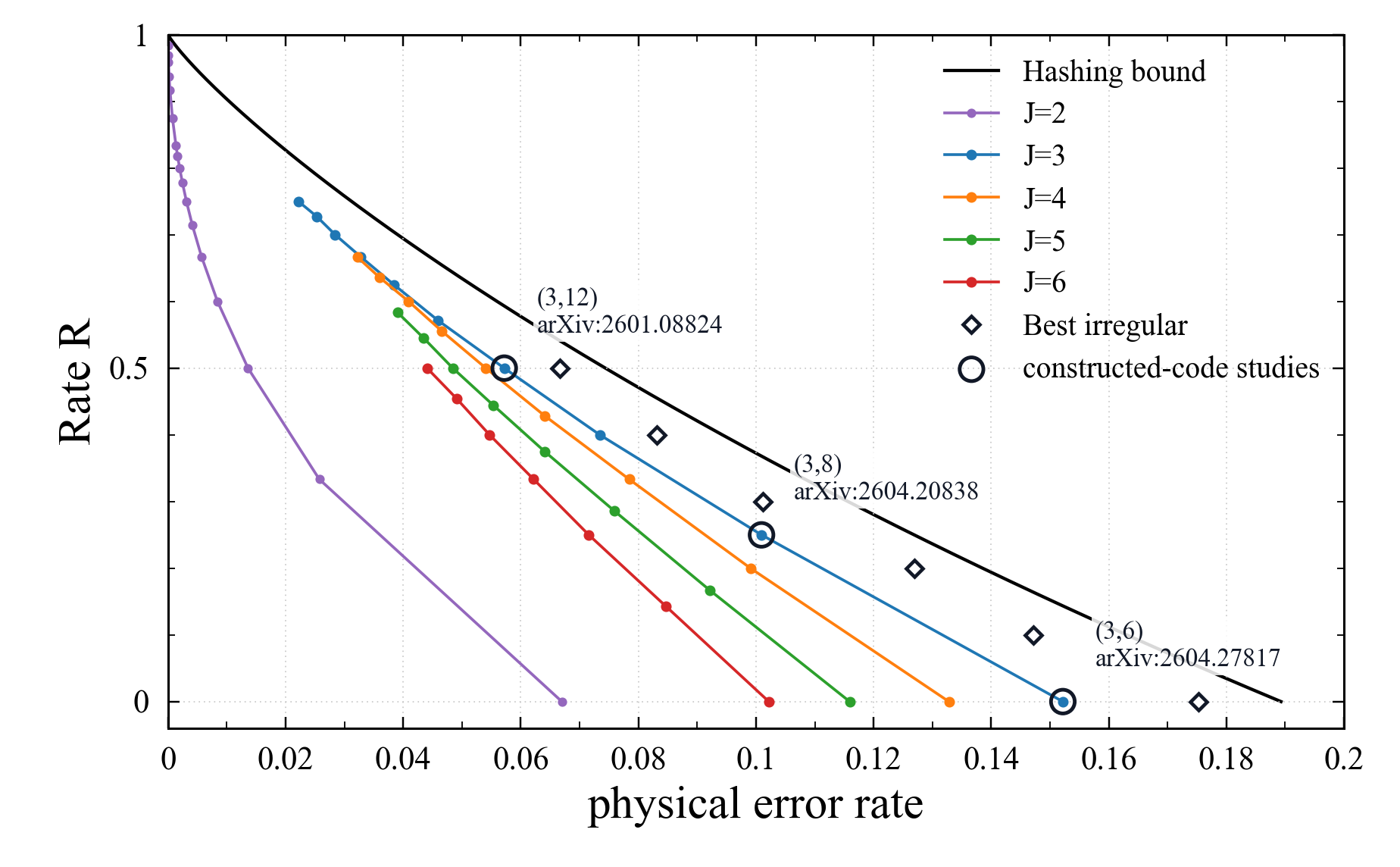
BP しきい値は、局所的に木状であると仮定したランダム LDPC 型の復号グラフ上で population density evolution を実行して求めています。 各物理誤り率 \(p\) に対し、脱分極チャネルから来る Pauli 誤りの事前分布を初期値とし、 その次数分布に従って変数ノード更新と検査ノード更新を反復します。 反復によりメッセージ分布が無誤り固定点へ収束する場合を BP 成功、非零の悪い固定点に残る場合を BP 失敗と判定し、 \[ p_{\mathrm{BP}} = \sup\{p:\text{density evolution が無誤り固定点へ収束する}\} \] を二分探索で推定しています。 正則曲線では \((J,L)\)-regular の次数分布を使い、設計レートは \(R=1-2J/L\) としています。 黒い菱形の非正則点では、下表の edge-perspective 分布 \(\lambda(x)\)、\(\rho(x)\) を使って同じ population DE を行っています。 したがって、図の値は有限長の構成済み CSS 符号を直接復号した実測しきい値ではなく、 同じ次数分布を持つ理想化されたランダム LDPC 型モデルの BP ベンチマークです。
なお \(J=2\) の正則系列では、population DE による収束・非収束の判定が 数値的に不安定になりやすいため、図の \(J=2\) 点は直接の収束判定ではなく 安定性条件から求めています。安定性の必要条件は \[ \mathfrak{B}(p)\lambda_2\rho'(1)\le 1, \qquad \mathfrak{B}(p)=2\sqrt{\frac{2p}{3}\left(1-\frac{2p}{3}\right)} \] です。\((J,L)=(2,L)\)-regular では \(\lambda_2=1\) かつ \(\rho'(1)=L-1\) なので、図の \(J=2\) のしきい値推定値は \[ \mathfrak{B}(p_{\mathrm{stab}})(L-1)=1, \qquad p_{\mathrm{stab}}(L)= \frac{3}{4}\left(1-\sqrt{1-\frac{1}{(L-1)^2}}\right), \qquad L=\frac{4}{1-R} \] から計算しています。
\((3,12)\)、\((3,8)\)、\((3,6)\) の正則点は、有限長実験が対応する DE 予測を支持している 参照点として重要です。丸で囲んだ \((3,12)\) 点は設計レート \(R=1-2\cdot 3/12=0.5\)、DE しきい値 \(p\simeq0.05719\) に対応します。この点は arXiv:2601.08824 で構成した girth 8 の \((3,12)\)-regular \([[9216,4612,\leq48]]\) 符号に対応し、 BP 復号と後処理により物理誤り率 \(p=0.04\) で FER \(10^{-8}\) に到達しています。 丸で囲んだ \((3,8)\) 点は設計レート \(R=1-2\cdot 3/8=0.25\)、DE しきい値 \(p\simeq0.10094\) に対応します。この点は arXiv:2604.20838 の girth 8 \((3,8)\)-regular CSS 基底符号から得られる CPM lift 符号に対応し、 物理誤り率 \(p=0.085\) で FER 約 \(10^{-8}\) に到達しています。 丸で囲んだ \((3,6)\) 点は設計レート \(R=1-2\cdot 3/6=0\)、DE しきい値 \(p\simeq0.15219\) に対応します。この点は arXiv:2604.27817 の girth 8 \((3,6)\)-regular CSS-LDPC 符号に対応し、 物理誤り率 \(p=0.1402\) で検証されています。
黒い菱形は、設計レート制約と標準的な安定条件のもとで最適化した非正則 edge-perspective 次数分布を表します。X 側と Z 側には同じ次数分布を用いており、しきい値は population density evolution により評価しています。ただし、これらの非正則点は設計目標であって、 その次数分布を持つ LDPC-CSS 符号を実際に構成して性能測定した結果ではありません。 また、それらの点が CSS 符号アンサンブルの漸近 BP しきい値を与えると証明しているわけでもありません。 問題意識は、「もし明示的な量子 LDPC-CSS 構成でそのような次数分布を実現でき、 復号時に同様の振る舞いが得られたら、 有限長性能はどこまでハッシング限界に近づけるか」です。
黒い菱形に対応する非正則ベンチマーク分布を、edge perspective の多項式 \(\lambda(x)=\sum_i \lambda_i x^{i-1}\) と \(\rho(x)=\sum_j \rho_j x^{j-1}\) として下表に示します。 X 側と Z 側には同じ分布を用いており、係数は小数第4位程度に丸めています。
| レート \(R\) | しきい値 \(p_{\mathrm{BP}}\) | \(\lambda(x)\) | \(\rho(x)\) |
|---|---|---|---|
| 0.0 | 0.17522 | \(0.2961x+0.2891x^{2}+0.0582x^{7}+0.3362x^{9}+0.0001x^{15}+0.0202x^{31}\) | \(0.0054x^{5}+0.9946x^{6}\) |
| 0.1 | 0.14715 | \(0.1895x+0.2890x^{3}+0.1093x^{5}+0.0937x^{9}+0.1028x^{23}+0.2157x^{31}\) | \(0.1778x^{9}+0.8222x^{10}\) |
| 0.2 | 0.12699 | \(0.1895x+0.2890x^{3}+0.1093x^{5}+0.0937x^{9}+0.1028x^{23}+0.2157x^{31}\) | \(0.8302x^{11}+0.1698x^{12}\) |
| 0.3 | 0.10114 | \(0.0585x+0.3366x^{2}+0.0933x^{3}+0.0097x^{5}+0.2733x^{9}+0.0024x^{23}+0.2261x^{31}\) | \(0.7667x^{13}+0.2333x^{14}\) |
| 0.4 | 0.08311 | \(0.0585x+0.3366x^{2}+0.0933x^{3}+0.0097x^{5}+0.2733x^{9}+0.0024x^{23}+0.2261x^{31}\) | \(0.3941x^{15}+0.6059x^{16}\) |
| 0.5 | 0.06661 | \(0.4969x^{2}+0.4270x^{15}+0.0631x^{23}+0.0130x^{31}\) | \(0.5113x^{19}+0.4887x^{20}\) |
BP 復号しきい値とは別に、同じ次数分布が最小距離の観点でどの程度有利かを調べるため、 正則 LDPC 型アンサンブルの平均重み分布に基づく距離ベンチマークも用いています。
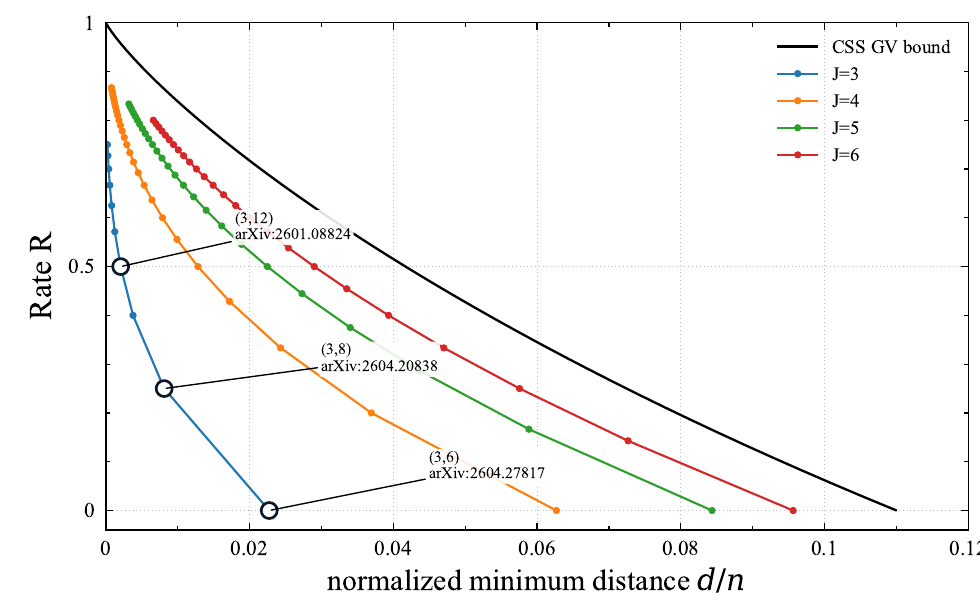
この図の色付き曲線は、有限長の構成済み CSS 符号の最小距離を直接計算したものではなく、 \((J,L)\)-regular なランダム LDPC 型アンサンブルの平均重み分布から得た典型的な相対距離のベンチマークです。 具体的には、相対重み \(\delta=d/n\) のコード語の期待個数を \(\mathbb{E}A_{\delta n}\doteq \exp(n\gamma_{J,L}(\delta))\) と書き、 最初に \(\gamma_{J,L}(\delta)=0\) となる正の \(\delta\) を、その \((J,L)\) 点の距離ベンチマークとして用いています。 ここで \[ \gamma_{J,L}(\delta) = h(\delta) +\frac{J}{L}\log P_L(x) -J\delta\log x -J h(\delta), \qquad P_L(x)=\frac{(1+x)^L+(1-x)^L}{2}, \] であり、\(x\) はサドルポイント条件 \[ \frac{xP_L'(x)}{P_L(x)}=L\delta \] を満たす正の解です。 図では各 \(J\) について \(L\) を動かし、CSS の設計レートを \(R=1-2J/L\) としてプロットしています。 黒線の CSS GV bound は \(R=1-2h_2(\delta)\) です。
今年の arXiv:2601.08824 、 arXiv:2604.20838 では、(3,12)-regular、(3,8)-regular、(3,6)-regular などの (3,*)-regular 量子LDPC符号族について、大ガース構成や良好な復号性能を与える具体例を示しています。 また、 arXiv:2511.04634 では qLDPC 符号のランダム構成法を試みましたが、大きなガースを系統的に得ることはできませんでした。 一方で、(3,*)-regular 符号の構成では、実験的には density evolution のベンチマークに近づく性能が見られる場合があるものの、 それを一般に保証する理論はまだありません。 さらに、 arXiv:2604.15307 では、これらを含む量子APM-LDPC符号に対して最小距離の上界 witness を多数与えています。 しかし、なぜこれらの構成がうまく機能するのかを統一的に説明する理論はまだ十分には確立されていません。
この問題群に関心のある方はご連絡ください。
arXiv:2603.24588 では、Hsu-Anastasopoulos 符号と MacKay-Neal 符号から、有限次数で Gilbert-Varshamov 境界を達成する量子LDPC符号を構成しています。 これは距離の観点では強い理論結果ですが、そのまま実用的なシンドローム測定や良好なBP復号性能まで与えるわけではありません。 とくに、有限次数・良い距離・実装可能性・復号容易性を同時に満たす構成へどう落とし込むかはまだ十分には分かっていません。 この文脈で、少なくとも次の2つの問題に関心があります。
つまり、GV境界到達という理論的性質を保ったまま、測定と復号の観点からも扱いやすい符号族へ発展させられるかが本質的な open problem です。
別の未解決問題として、実際に符号構成が可能であり、かつ density evolution によって BP 復号性能を予測できる qLDPC 符号アンサンブルを提案したいと考えています。
arXiv:2511.04634 のランダム構成法では qLDPC 符号のアンサンブル化を試みましたが、大きなガースを保つことはできませんでした。 他方で、今年の (3,*)-regular 構成では実験的に DE ベンチマークに近い性能が観測される場合があるものの、 その挙動を一般に予測するアンサンブル理論はまだありません。 そのため、有限長で実装可能な構成と、アンサンブル極限での解析可能性を両立させる枠組みはまだ十分に整っておらず、 構成論と復号性能解析を自然に結び付けるモデルの確立が open problem です。
可換性条件 \(H_XH_Z^{\mathsf T}=0\) は本質的ですが、これを sparse regular な二元検査行列のレベルで直接課すと、 エッジ配置の自由度が大きく失われ、4-cycle や 6-cycle が増えやすくなります。 その結果、ガース、距離、BP 復号性能が悪化します。 これを「直交性の壁」と呼んでいます。
もう少し広い意味では、直交性の壁とは、古典 LDPC 符号で有効だった設計思想を量子 LDPC 符号に自由に持ち込めなかった、 という障害でもあります。 古典符号では、次数分布、ガース、短サイクルの除去、density evolution による BP しきい値の最適化などを比較的自由に組み合わせて設計できます。 しかし CSS 符号では \(H_X\) と \(H_Z\) が直交しなければならないため、 片方の Tanner graph を良くしようとすると、もう片方との可換性が崩れたり、逆に直交性を守ると短サイクルや低重み構造が生じたりします。 そのため、古典 LDPC の設計原理をそのまま使うことが難しかったわけです。
提案構成では latent matrix と parent matrix を導入し、直交性は active matrix に対してのみ課すことで、 正則性を保ちながら短サイクルを避けています。 これにより、直交性を満たしつつ、ガース制御や次数分布設計などの古典 LDPC 的な設計自由度を量子 LDPC 符号の構成に持ち込めるようになります。 つまり「直交性の壁を突破する」とは、単に一つの可換な符号を作るという意味ではなく、 直交性のために失われていた古典符号の設計思想を、量子 LDPC 符号設計の中で再び使えるようにする、という意味を含んでいます。
参考: arXiv:2601.08824
もっともな懸念です。非常に長い符号長では距離下界を厳密に計算するのが難しく、 上界だけでは構成の本当の有効性を判断しづらいことがあります。 より短い例であれば、距離下界を計算しやすくなり、距離が本当に改善しているかを確認しやすくなります。
最新版の arXiv:2601.08824 では、girth 8 と、できれば最小距離 48 を保ちつつ、より短い符号長を狙うための制約緩和の方向性にも触れています。
参考: arXiv:2601.08824
強い BP 性能を得るには 4-cycle を避けるだけでは不十分で、6-cycle も除去する必要があります。 一方、 arXiv:2601.08824 で述べているように、一般化 Hagiwara-Imai 型で列重みが 3 以上の場合、8-cycle は避けられないため、 実際の目標は girth 8 になります。
参考: K. Kasai, “Breaking the Orthogonality Barrier in Quantum LDPC Codes,” arXiv:2601.08824, 2026
density evolution のベンチマークでは列重み 3 が最もよい性能を示します。 また、提案構成で実現できる最小の行重みが 12 なので、\((3,12)\)-regular は自然な設計点になります。
参考: arXiv:2601.08824
行重みだけを見ると不利に見えますが、BP 復号性能を決める主な要因は行重み単独ではありません。 \((3,12)\)-regular の場合、列重みは 3 に保たれており、各変数ノードが受け取る情報の局所構造は比較的よい形にあります。 さらに、4-cycle と 6-cycle を避けて girth 8 にすることで、BP の初期反復でメッセージが独立に近くなり、 density evolution で予測される性能に近づきやすくなります。 つまり、理想シンドロームモデルでのウォーターフォール性能は、基本的には DE が与えるしきい値と有限長効果で決まります。
行重み 12 は、検査ノードが一度に多くの変数を結ぶという意味では大きいですが、 レート \(R=1-2\cdot3/12=1/2\) を実現するための設計点でもあります。 高レートを保つには検査数を相対的に少なくする必要があり、その結果として行重みは大きくなります。 重要なのは、行重みを大きくしても短いサイクルや有害な低重み構造を増やさないように配置を制御することです。
また、実験で使っている joint BP は \(X\) 成分と \(Z\) 成分を別々に復号するのではなく、 qubit ごとの Pauli 誤りの局所相関を保ったまま復号します。 さらに残った trapping cycle 型の誤りは軽量な後処理で補正します。 そのため、行重みが 12 であっても、ガース、次数分布、相関を保つ復号、後処理が組み合わさることで高い復号性能が得られます。
もちろん、行重み 12 は syndrome 測定回路では不利にもなります。 一つの検査が多くの qubit に触れるため、測定誤りや回路中の誤りが蓄積し、実効的なノイズは大きくなり得ます。 それでも \((3,12)\)-regular LDPC 符号は、DE が示す理想復号性能と実際の joint BP 性能に大きな余裕があるため、 その測定回路由来の不利を上回るだけの復号性能を持っている、というのが現在の理解です。 したがって、回路レベルノイズまで含めた最終評価では、行重みによるノイズ増加と、符号そのものの強い復号性能とのバランスを見る必要があります。
そのとおりだと思います。古典 LDPC 符号の理論は、次数分布、ガース、density evolution、最小距離などについて 非常に強い設計原理を与えてくれますが、量子誤り訂正ではそれだけでは足りません。 量子符号では \(H_XH_Z^{\mathsf T}=0\) という直交性制約があり、さらに syndrome 測定回路、 測定誤り、データ誤りと測定誤りが混ざった時空間的な復号問題、そしてデバイス上で実際に実装できる相互作用構造を同時に考える必要があります。
したがって、ここでの立場は「古典 LDPC の構成法をそのまま量子符号に移植する」というものではありません。 古典 LDPC から得られる良い局所構造や BP しきい値の直感を出発点にしつつ、 CSS 直交性、低重み logical operator の回避、復号器の構造、syndrome extraction のしやすさ、 回路レベルノイズ下での性能までを含めて、符号と実装と復号を共同設計する必要があります。 この意味で、古典符号理論は重要なベンチマークですが、最終的な量子 LDPC 符号設計は別の制約を持つ設計問題です。
例えば arXiv:2601.08824 では、古典 LDPC 的な大ガース構造を保ちながら CSS 直交性と低重み構造の問題を避けることを目指しています。 また arXiv:2604.16209 では、再構成可能な原子配列での syndrome extraction、原子再配置の制約、階層的復号器、circuit-level noise model まで含めて評価しています。 つまり、古典 LDPC の良い性質を利用しつつ、量子計算に必要な回路・ノイズ・復号の制約に合わせて符号を設計する、というのが基本方針です。
基本の復号法は joint belief propagation (joint BP) です。 CSS syndrome decoding を、\(X\) 側と \(Z\) 側の二つの Tanner graph が各 qubit の局所 joint prior で結合された factor graph として書き、その factor graph 上で sum-product algorithm を実行します。 これにより、\(X\) 成分と \(Z\) 成分を別々に復号するのではなく、Pauli 誤りの局所相関を保ったまま BP を行えます。
実験では、この joint BP に軽量な後処理を組み合わせています。 特に、PP-flip や PP-OSD により trapping cycle 由来の残差誤りを補正し、 複雑度を大きく増やさずに低 FER 領域を改善しています。
「\(\le 48\)」は最小距離の上界を意味します。 この上界は構成に対応する potential matrix から導かれています。 とくに長大符号では説得力のある下界を得るのが難しく、短い例を探る動機の一つにもなっています。
density evolution は、無限長かつ木近似の下で BP のメッセージ分布がどう推移するかを追う理論です。 しきい値は、平均的に BP が成功する領域と失敗する領域の境目を表します。 これは有限長での保証ではなく、解析的なベンチマークです。
参考: arXiv:2601.08824
ここでいう CSS 符号型の非直交符号とは、\(X\) 側と \(Z\) 側に対応する二つの LDPC 型検査行列を考える一方で、 量子 CSS 符号に必要な直交条件 \(H_XH_Z^{\mathsf T}=0\) はまだ課さない、という理想化されたアンサンブルです。 density evolution では、この非直交アンサンブルを古典 LDPC 符号に近い木状グラフモデルとして扱い、 BP 復号のメッセージ分布が無限長極限でどう変化するかを追います。
実際の計算では、メッセージ分布を閉形式で書けないことが多いため、 多数のサンプルで分布を近似して更新する Monte Carlo density evolution (population density evolution)を使います。 これはメッセージ分布そのものを大きな標本集合として保持し、変数ノード更新・検査ノード更新・チャネル更新をランダムサンプリングで反復する方法です。
重要なのは、これは構成した有限長 CSS 符号の性能保証ではなく、ベンチマークだという点です。 直交性、短サイクル、有限長効果、縮退性、\(X/Z\) 側の相関は、この理想化から外れます。 したがって、この DE しきい値は「同じ次数分布を持つ古典 LDPC 的な理想モデルなら、どの程度の BP 性能が期待されるか」を測る基準として使います。
この基準と実際に構成した直交 CSS 符号のシミュレーションを比べることで、 直交性制約を課したあとも古典 LDPC 的な BP 性能がどれだけ保たれているかを評価できます。
参考: D. Divsalar, S. Dolinar, C. Jones, and K. Andrews, “Capacity-Approaching Protograph Codes,” IEEE J. Sel. Areas Commun., 2009, T. Richardson and R. Urbanke, Modern Coding Theory, Chs. 3-5 and App. B, 2008
density evolution が BP 復号性能のベンチマークであるのに対して、 最小距離解析は、同じ次数分布を持つ古典 LDPC 的な理想アンサンブルで 低重み符号語がどの程度現れるかを見るベンチマークです。 CSS 符号型の非直交モデルでは、\(X\) 側と \(Z\) 側の検査行列をいったん別々の古典 LDPC 検査行列として扱い、 それぞれの kernel に含まれる低重みベクトルの期待個数や重み分布の成長率を調べます。
典型的には、重み \(\omega n\) のベクトルが検査を満たす期待個数の指数率を評価します。 その成長率が負になる重み領域では、ランダムなアンサンブル中にその重みの符号語が現れにくいと解釈できます。 これにより、古典 LDPC 的な意味で最小距離が線形に伸びそうか、あるいは低重み構造が出やすいかを判断します。
ただし、これは構成した有限長の量子 CSS 符号の最小距離保証ではありません。 実際の CSS 距離では、直交条件 \(H_XH_Z^{\mathsf T}=0\)、row space による同値、縮退性、 有限長の短サイクルや特殊な代数構造が効きます。 したがって、この解析は「直交性を課す前の古典 LDPC 的な距離の期待値」を見るためのベンチマークです。
このベンチマークと、実際に構成した直交 CSS 符号に対する低重み探索や上界・下界の計算を比べることで、 直交性制約や構成上の規則性がどれだけ低重み論理演算子を生みやすくしているかを評価できます。
参考: R. G. Gallager, “Low-Density Parity-Check Codes,” IRE Trans. Inf. Theory, 1962, S. Abu-Surra, D. Divsalar, and W. E. Ryan, “Enumerators for Protograph-Based Ensembles of LDPC and Generalized LDPC Codes,” IEEE Trans. Inf. Theory, 2011, T. Richardson and R. Urbanke, Modern Coding Theory, Ch. 7, 2008
その懸念は自然です。LDPC 符号はランダム性を含む構成なので、 ランダムに選んだ一つのインスタンスがアンサンブル平均から大きく外れる可能性を考える必要があります。 古典 LDPC 符号理論では、次数分布だけでアンサンブルを規定する標準的な場合について concentration theorem があり、 十分大きな符号長では、BP 復号性能が density evolution で予測される平均性能の周りに高確率で集中することが知られています。
提案する CSS 構成は直交性や代数的配置を含むため、Modern Coding Theory の concentration theorem をそのまま適用できるわけではありません。 また実際の設計では、次数分布だけでなく、ガース、符号長、最小距離に関する上界評価などの追加制約も課しています。 それでも経験的には、これらの制約を入れた後に残る自由度からランダムにインスタンスを選ぶと、 古典 LDPC アンサンブルで見られるのと同様の自己平均化、つまり平均性能への集中が観測されています。
実験的にも、同じ設計パラメータを持つ複数のインスタンスで FER 曲線や BP のウォーターフォール位置を比較すると、 極端に異なる挙動ではなく、density evolution ベンチマークに近い範囲にまとまる傾向が見られます。 一方で、エラーフロア領域は注意が必要です。人間が興味を持つ誤り率のスケールは非常に小さく、 ウォーターフォール領域よりも稀な有害構造や有限長効果に敏感なので、 「平均に集中している」という観察だけで安全と言い切るべきではありません。 現時点での位置づけは、ウォーターフォール性能については古典 LDPC の concentration theorem と同じ型の現象を期待し、 有限長実験でもその傾向を確認しているが、CSS 直交制約込みの厳密な concentration theorem とエラーフロア解析は今後の理論課題である、というものです。
参考: T. Richardson and R. Urbanke, Modern Coding Theory, Ch. 3 and App. C, 2008, arXiv:2601.08824
特徴の一つは、できるだけランダムネスを入れている点です。 つまり、正則性とガース制約を満たす符号のクラスの中で、できるだけランダムに構成するようにしています。 完全に自由なランダム構成では CSS 可換性や大ガースを保つのが難しいため、 必要な制約を課した上で、その制約の範囲内では偏りをなるべく減らす、という立場です。
参考: arXiv:2601.08824
完全に自由なランダム符号を作るのではなく、まず設計したい符号アンサンブルを決めます。 具体的には、次数分布、ガース、符号長、CSS 直交性、さらに最小距離に関係する低重み構造の上界評価などの条件を指定します。 最小距離そのものを大きな符号長で厳密に保証するのは難しいため、実際には低重み論理演算子の探索や上界評価を使って候補を絞ります。
そのうえで、これらの条件を満たす候補集合の中から、シフト量、APM 要素、有限体係数などをランダムに選びます。 つまり、構造を完全に固定して一つの符号を作るのではなく、 「正則性・大ガース・直交性・距離上界評価を満たす」という制約の範囲内でランダムに符号インスタンスを選ぶことで、 構成にランダムネスを注入しています。
この方針により、CSS 可換性のような量子符号に必要な制約を保ちながら、 古典 LDPC 符号で重要なランダム性と自己平均化の効果をできるだけ残すことを狙っています。
参考: arXiv:2601.08824
古典符号理論でよく知られている二つの事実を活用しています。 第一に、列重み 2 の非二元 LDPC 符号は反復復号で非常によい性能を示しうること、 第二に、列重み 2 だと Tanner graph の短サイクル除去を柔軟に行いやすいことです。
これを affine permutation matrix (APM) 配置と組み合わせることで、 直交性と大ガースを両立し、error floor を抑えながら鋭い threshold 的挙動を実現しています。
列重み2の二元検査行列は、各変数ノードを二つのチェックノードを結ぶ辺と見なすことで、 通常のグラフの接続行列と同じ形になります。 このとき符号語は、各チェックノードに偶数本の辺が入る部分グラフ、つまりサイクルの和に対応します。 したがって最小距離は、そのグラフの最短サイクル長で上から抑えられます。
一方、LDPC では行重みも有界なので、対応するグラフは有界次数グラフです。 有界次数グラフで頂点数を増やしても、最短サイクル長は高々 \(O(\log n)\) 程度にしか伸びません。 そのため、列重み2の二元 LDPC 符号では、最小距離が符号長に比例して伸びることは期待できません。
参考: R. G. Gallager, “Low-Density Parity-Check Codes,” IRE Trans. Inf. Theory, 1962, T. Richardson and R. Urbanke, Modern Coding Theory, Chs. 2 and 7, 2008
BEC 上の \((d_v,d_c)\)-正則 LDPC 符号の density evolution を見ると理由が分かります。 消去確率を \(\epsilon\)、\(l\) 回目の変数ノードからチェックノードへの消去メッセージ確率を \(x_l\) とすると、更新式は \[ x_{l+1} = \epsilon\left(1-(1-x_l)^{d_c-1}\right)^{d_v-1} \] です。
列重み2、つまり \(d_v=2\) の場合、この式は \[ x_{l+1} = \epsilon\left(1-(1-x_l)^{d_c-1}\right) = \epsilon(d_c-1)x_l+O(x_l^2) \] となります。 したがって 0 点近傍での傾きは \(\epsilon(d_c-1)\) です。 BP が成功するには 0 固定点が安定である必要があるため、 \(\epsilon(d_c-1)<1\)、すなわち \(\epsilon<1/(d_c-1)\) が必要になります。
ただし、これは二元 LDPC 符号として見た場合の話です。 同じ列重み2でも、非二元体上の LDPC 符号として扱うと、各メッセージが単なる 0/1 ではなく体要素上の確率分布になり、 BP 復号で使える情報量が増えます。 そのため、とくに高レート領域では、列重み2の非二元 LDPC 符号が二元の場合より大きく性能改善することがあります。 npj Quantum Information 論文の構成でも、この有限体拡大の考え方を CSS 構成と組み合わせることで、 列重み2の利点を活かしつつ高い復号性能を得ています。
二元の場合、この上限は行重み \(d_c\) が大きくなる高レート領域で特に小さくなります。 一方、列重み3以上では 0 点近傍の一次項が消えるため、同じような一次の安定性制約を受けません。 これが、列重み2の正則二元 LDPC 符号の BP スレッショルドが低くなりやすく、 一方で多元化により性能改善が期待できる基本的な理由です。
参考: R. G. Gallager, “Low-Density Parity-Check Codes,” IRE Trans. Inf. Theory, 1962, T. Richardson and R. Urbanke, Modern Coding Theory, Ch. 3, Sec. 3.9, and App. B, 2008, D. Komoto and K. Kasai, “Quantum error correction near the coding theoretical bound,” npj Quantum Information, 2025
いいえ。density evolution の結論はアンサンブル極限での漸近的な主張であって、 個々の次数2の列を全面的に禁止するものではありません。 非正則 LDPC 設計では、少数の次数2列を意図的に使うこともあります。
本質的なのは、次数2列が多すぎないか、またそれらが長い鎖や小さな stopping set、 trapping set を作りやすい局所配置になっていないか、という点です。 したがって設計原理としては、「次数2を絶対に使わない」ではなく、 「どれだけ使うか、どこに現れるかを慎重に制御する」が適切です。 古典符号でよく知られている例として、IRA (Irregular Repeat-Accumulate) 符号では、accumulator 部分に由来する次数2の変数ノードが自然に現れます。 それでも全体設計が適切なら、実用上よい復号性能を示します。
参考: A. Roumy, S. Guemghar, G. Caire, and S. Verdu, “Design Methods for Irregular Repeat-Accumulate Codes,” IEEE Trans. Inf. Theory, 2004, H. Jin, A. Khandekar, and R. McEliece, “Irregular Repeat-Accumulate Codes,” 2000, arXiv:2506.15636
提案符号の最小距離は、符号長に対して線形に伸びるとは限りません。 それでも BP 復号性能がよいのは、density evolution の観点では主に重要なのが列重みと行重みであり、 最小距離の漸近成長そのものではないからです。
最小距離は error floor を特徴付ける指標として重要ですが、 優れた iterative decoding 性能のために、必ずしも線形成長する最小距離が必要なわけではありません。 これは古典 LDPC 符号理論から得られる重要な教訓です。
参考: arXiv:2506.15636
主な要素は4つです。
(i) short cycle を避けるための APM 構成、
(ii) 非二元体 \(\mathbb{F}_q\) 上での joint BP 復号、
(iii) 行列要素の選択による最小距離の最適化、
(iv) 残差誤りを除去する軽量な後処理です。
従来の CSS 符号の BP 復号では、\(X\) 誤りと \(Z\) 誤りを二つの独立な二元 LDPC 復号問題として 別々に扱うことがよくあります。 しかし depolarizing noise などでは、各 qubit 上の \(X\) 成分と \(Z\) 成分は独立ではなく、 \(Y\) 誤りを通じて局所的に相関しています。 提案する joint BP では、\(X\) 側と \(Z\) 側の二つの Tanner graph を各 qubit の local joint prior で結合した factor graph を作り、その上で sum-product algorithm を実行します。 したがって、Pauli 誤りの局所相関を捨てずに syndrome decoding を行える点が大きな違いです。
もう一つの見方として、Pauli ラベル \(I,X,Y,Z\) を状態とする four-state BP があります。 arXiv:2605.05132 では、joint BP と four-state BP は、局所状態のラベル付けと不要な二元成分の周辺化を除けば、 同じ posterior weight、message、belief を計算していることが示されています。 つまり joint BP は、CSS 構造を明示した二元 factor graph 表現であり、 従来の分離復号より相関を保ちつつ、four-state BP と同じ本質をより CSS 符号に合った形で書いた復号法と見ることができます。
stabilizer weight とは、各 stabilizer 生成子に含まれる非自明作用の数です。 Tanner graph の言葉では、対応する検査ノードの次数に相当します。 実装上は、これは syndrome measurement の複雑さにも直接関係します。
参考: arXiv:2506.15636
いいえ。最終的に得られるのは二元 CSS 符号であり、qubit を保護しています。 \(\mathbb{F}_q\) の各要素は \(e\times e\) の companion matrix に展開されるので、 構成の途中で非二元表現を使っていても、最終的な符号は二元です。
参考: arXiv:2506.15636
基本的な考え方は Hagiwara-Imai 構成の一般化です。 検査行列の循環シフト位置に affine permutation matrix を配置し、 シフト量と APM 要素を適切に選ぶことで、 非二元行列 \(H_{\Gamma}\) と \(H_{\Delta}\) を \(\mathbb{F}_q\) 上で直交させます。
その後、各体要素を companion matrix に展開することで、 \(H_XH_Z^{\mathsf T}=0\) を満たす二元行列 \(H_X,H_Z\) が得られます。 これにより、直交性と大ガースを両立できます。
参考: arXiv:2506.15636
中間的な候補として自然なのは、有限環 \(R\) 上の1次元アフィン群 \( \mathrm{AGL}_1(R)=R\rtimes R^{\times} \) です。 これは平行移動と乗法作用の両方を含むため、単なる一般化置換・モノミアル作用よりも豊かな構造を持ちながら、 代数的にまだ扱いやすく、明示的な符号構成にも使いやすい群です。
特に、有限可換主イデアル環上の affine group は、柔軟性と可解析性のバランスがよく、 量子LDPC符号構成に使う非可換群として有望だと考えています。 具体例として、\(R=\mathbb{Z}/4\mathbb{Z}\) のとき \(R^{\times}=\{1,3\}\) なので、 \(\mathrm{AGL}_1(\mathbb{Z}/4\mathbb{Z})\) は 8 元の非可換群になります。 また、\(R=\mathbb{F}_q\) のときの \(\mathrm{AGL}_1(\mathbb{F}_q)\) も、平行移動とスカラー作用を併せ持つ基本的な非可換群の例です。
参考: arXiv:2604.02063
LDPC 符号の復号性能は、横軸に通信路の誤り率、縦軸に FER や BER を対数スケールで描くと、 典型的には二つの領域に分かれて見えます。 まず、しきい値付近では誤り率が少し改善するだけで復号失敗率が急激に下がります。 この急降下する部分をウォーターフォール領域と呼びます。 BP 復号では、この領域の位置は density evolution のしきい値や有限長スケーリングと深く関係しています。
ウォーターフォール領域では、失敗の主な要因は density evolution 方程式の非自明な不動点や、 有限長ゆらぎによって復号過程が悪い側へ落ちることです。 その結果として、BP 復号のあとに符号長に比例する大きさの誤りが残ることがあります。
さらに誤り率を下げていくと、曲線の下がり方が急に鈍くなり、ほぼ水平に見える領域が現れることがあります。 これをエラーフロア領域と呼びます。 ここでは平均的な密度発展よりも、最小距離を与える低重み logical operator や、 BP 復号の収束に悪影響を与える小さな trapping set など、まれな局所構造が支配的になります。 この領域で残る誤りの大きさは通常 \(O(1)\) であり、符号長には依存しません。 したがって、ウォーターフォール性能が良いことと、非常に低い FER までエラーフロアが出ないことは、関連はありますが別の設計課題です。
消失通信路上の LDPC 符号では、ウォーターフォール領域の有限長スケーリングがかなりよく理解されています。 density evolution のしきい値 \(p_{\mathrm{th}}\) の近くでは、復号の成否は 「有限長のランダムなゆらぎにより、実効的なしきい値がどちら側にずれるか」でほぼ決まります。 このゆらぎは多数の局所的な寄与の和として現れるため、中心極限定理的に正規分布で近似できます。
その結果、ブロック長を \(n\)、物理誤り率を \(p\) とすると、失敗確率は模式的に \[ P_{\mathrm{fail}}(p,n) \approx Q\!\left(\frac{p_{\mathrm{th}}-p}{\alpha n^{-1/2}}\right) \] のような形になります。 ここで \(Q(x)\) は標準正規分布の右側尾確率です。 つまり、有限長では本来鋭いしきい値が幅 \(O(n^{-1/2})\) で丸まり、その丸まり方が正規分布の尾、すなわち Q 関数で表されます。
厳密に解明されているのは主に binary erasure channel の場合ですが、 同じような有限長スケーリングはより一般の反復復号でも経験的によく観測されます。 そのため、BP の FER 曲線を Q 関数型でフィットするのは、ウォーターフォール領域の有限長効果を要約する自然な方法です。
従来の量子LDPC符号は、低レート、高い error floor、スケーラビリティ不足、 重い後処理の必要性といった問題を抱えています。 その結果、符号長を伸ばしても性能が十分には伸びず、hashing bound からも遠いままです。 私たちの研究は、非零レートかつ効率的な復号を保ちながら、hashing bound に近づく構成を目指しています。
threshold 現象や error floor の有無は、非常に大きな符号長でないとはっきり見えてきません。 その領域で sharp transition や error floor の抑制を示すことが、スケーラビリティの最も強い証拠になります。
いいえ。ここでの解析は、ゲート、stabilizer measurement、recovery がすべて理想的であるという仮定の下で行っています。 目的は、工学的制約とは切り分けて、符号理論そのものの限界を見ることです。
一方で、関連する arXiv:2604.16209 では、reconfigurable atom arrays 上での実装を意識し、syndrome extraction と atom rearrangement の制約を含めた circuit-level noise model を扱っています。 つまり、こちらのQ&Aで述べている理想測定モデルは符号理論ベンチマークであり、 サーキットレベルノイズまで含めた実装寄りの評価は別論文で進められています。
真の誤りと推定誤りの差が dual code に属するかどうかで判定します。 すなわち、\((x+\hat{x})\in C_X^{\perp}\) かつ \((z+\hat{z})\in C_Z^{\perp}\) なら成功とみなします。 これは両者が stabilizer の差にすぎず、同じ logical state を表しているためです。
Koki Okada氏との共同研究 「A Two-Branch Finite-Field Construction for Regular CSS LDPC Bases」 を arXiv に公開しました。
二分岐の有限体構成により、正則性・CSS直交性・同種4-cycle除去を有限個の商剰余類条件に帰着します。 詳細例では \(\mathbb F_{16}\) 上の \((3,10)\)-正則基底符号を 64-fold CPM lift し、 \([[10240,4108,10\le d\le32]]\) CSS符号を構成しています。
この \([[10240,4108,10\le d\le32]]\) 符号について、64-fold lift の検査条件、距離 witness、FER 図を 符号構成データページ にまとめました。
Boston研究訪問で使用したスライドと発表原稿を公開しました。 滞在期間は2026年5月11日から5月15日までで、QuEra、Harvard、MITを訪問し、研究発表と議論を行いました。 CSS制約の下で、古典LDPC符号の設計原理を量子LDPC符号へ持ち込む研究について説明しています。
📄 スライド(Boston Research Visit, 2026)
📄 発表原稿(Boston Research Visit, 2026)
Koki Okada氏との共同研究「High-Girth Regular Quantum LDPC Codes from Affine-Coset Structures」を arXiv に公開しました。
本研究では、girth 8 の (3,8)-regular CSS 基底符号から P=32 の CPM lift により [[16384,4142,≤40]] 量子LDPC符号を構成し、BP復号と後処理により p=0.085 で FER 約 10-8 を観測しました。
復号器、P=32 の検査行列データ、1 trial の反復追跡例を GitHub で公開しています。 リフト係数、MatrixMarket形式の \(H_X,H_Z\)、FER 図は 符号構成データページ にもまとめています。
新しいプレプリント「Heuristic Search for Minimum-Distance Upper-Bound Witnesses in Quantum APM-LDPC Codes」を arXiv に公開しました。
本研究では、アフィン置換行列から構成される量子 APM-LDPC 符号に対し、低重みの非スタビライザ論理代表を探索・検証することで、最小距離の上界を認証する枠組みを与えています。 潜在行関係、制限付きリフト部分空間、CRT 構造、cycle-8 trapping set、復号失敗残差などを統一的に扱います。
候補となる witness は、明示的な kernel 条件と row-space 除外条件を満たすことを確認したうえで採用しており、探索されたパラメータ範囲における認証済みの上界を報告しています。
新しいプレプリント「Cross-Commuting Nonabelian Squares in Affine Groups over Finite Commutative Principal Ideal Rings」を arXiv に公開しました。
本研究では、有限可換主イデアル環上の1次元アフィン群において、2つの族が互いには可換でありながら、それぞれの族の内部では非可換性を保つ構造がいつ存在するかを分類しています。 剰余環 \(\mathbb{Z}/n\mathbb{Z}\) についても完全な判定条件を与えており、アフィン置換に基づく量子符号構成の代数的背景にも関係します。
京都大学・基礎物理学研究所(YITP)で開催される 「2026 YITP Fault-Tolerant Logical Processing Workshop」(2026年9月28日〜10月9日)において、 招待講演を行うことになりました。
第8回 Quantum Error Correction (QEC26) のプログラム委員を務めることになりました。会議は 2026年6月7日〜12日、米国カリフォルニア州サンタバーバラで開催予定です。
新しいプレプリント「Breaking the Orthogonality Barrier in Quantum LDPC Codes」を arXiv に公開しました。
量子LDPC符号における直交性制約に焦点を当て、制約を乗り越えるための理論的枠組みと構成を提示しています。
河本大輝さん(東京科学大学修士課程修了)と笠井健太准教授(東京科学大学)の共著論文 「Quantum error correction near the coding theoretical bound」が、 npj Quantum Information に掲載されました。
本研究では、LDPC符号に基づく量子誤り訂正方式により、符号理論的限界(ハッシング限界)に迫る高効率な符号設計を実現しました。 また、数十万規模の論理量子ビットを効率的に処理できることを示し、スケーラブルな量子計算の実現に向けた重要な一歩となりました。
論文は npj Quantum Information (Nature) にて公開されています。
npj Quantum Information に掲載された論文 「Quantum error correction near the coding theoretical bound」が、 複数のニュースメディアで紹介されました。
これらの記事では、提案手法が量子誤り訂正の符号理論限界に迫る性能を持ち、 大規模量子コンピュータの実現に向けた重要な進展であると紹介されています。
量子誤り訂正における縮退誤りのデコードに関する新しい研究成果 「Quantum Error Correction Exploiting Degeneracy to Approach the Hashing Bound」を arXiv にて公開しました。
本研究では、多元LDPC符号の構造と縮退性を組み合わせた新しい復号アルゴリズムを提案し、エラーフロアの改善と符号理論的限界への接近を実証的に示しています。 実験は depolarizing channel 上で行われ、10万論理量子ビット規模での高性能な誤り訂正を実現しました。
国際会議 ISTC 2025 (13th International Symposium on Topics in Coding) において、以下の論文およびポスター発表が採択されました。
本研究では、非巡回型のアフィン置換行列を用いた新しい量子APM-LDPC符号の構成法を提案し、従来の量子QC-LDPC符号の制約を超えたgirth-16の設計可能性を示しました。 ポスター発表では、多元LDPC符号を用いた量子誤り訂正の最近の発展と、今後の高ガースの符号構成法に関する展望を概観します。
会議は 2025年8月18日〜22日、米国ロサンゼルスにて開催予定です。 詳細は ISTC 2025公式サイト をご覧ください。
笠井健太准教授(東京科学大学)の研究「Perspectives on Degeneracy and Structure in Non-Binary LDPC Code-Based QEC」が、 国際会議 ISIT 2025 におけるワークショップ Quantum Information – Open Problems, Impact, and Challenges (Q-PIC) にてポスター発表として採択されました。
本ワークショップは、量子情報分野の未解決問題やその波及的影響を議論する場として設けられており、 多元LDPC符号に基づく量子誤り訂正の構造と縮退性(degeneracy)に関する新たな視点が提示されます。
ポスターは 2025年6月24日(火)9:30~、ミシガン大学のRackham Graduate Schoolにて展示され、 笠井准教授による30秒間のピッチトークおよび質疑応答が予定されています。
ワークショップの詳細は Q-PIC公式サイト をご覧ください。
笠井健太准教授(東京科学大学)の研究「Follow-Up Study on “Efficient Mitigation of Error Floors in Quantum Error Correction using Non-Binary LDPC Codes”」が、 国際会議 ISIT 2025(IEEE International Symposium on Information Theory) の Recent Results Poster Session に採択されました。
本セッションは、6月23日(月)14:30–15:50 にミシガンリーグのボールルームで開催予定であり、 最新の研究成果を速報的に紹介するポスター発表の場として設けられています。
関連論文の事前版は arXiv にてご覧いただけます。
詳細は ISIT 2025公式サイト をご覧ください。
笠井健太准教授(東京科学大学)の研究「Towards Practical Quantum Error Correction: Near-Optimal Performance and Floor Mitigation via Non-Binary LDPC Codes」が、 国際会議 QEC25(Quantum Error Correction 2025) にてポスター発表として採択されました。
本研究では、非二元LDPC符号を用いて量子誤り訂正の現実的実装におけるエラーフロア問題の緩和を実現し、実用的な復号法の下で符号理論的限界に近い性能を達成しています。
ポスターセッションの採択率は40%未満と非常に競争が激しく、理論計算機科学分野の主要国際会議に匹敵するレベルの選考となりました。
会議の詳細は QEC25 公式サイト をご覧ください。
第52回量子情報技術研究会(QIT52)にて、河本大輝さんと笠井健太准教授が、 アフィン置換行列を用いた量子LDPC符号の新たな構成法に関する研究をポスター発表します。
発表タイトル:「短いサイクルを持たないアフィン置換行列型量子LDPC符号の明示的構成法の提案」
著者: 河本 大輝(東京科学大学), 笠井 健太(東京科学大学)
発表形式:ポスターセッション(2025年5月28日 18:00–19:30、静岡大学 浜松キャンパス)
同じくQIT52にて、笠井健太准教授が、多元LDPC符号を用いた量子誤り訂正手法におけるエラーフロアの緩和についての研究を発表します。
発表タイトル:「多元LDPC符号に基づく量子誤り訂正におけるエラーフロアの緩和に向けた検討」
著者: 笠井 健太(東京科学大学)
発表形式:ポスターセッション(2025年5月28日 18:00–19:30、静岡大学 浜松キャンパス)
第51回量子情報技術研究会において、河本大輝さんが優れた学生発表を行い、「学生発表賞」を受賞しました。
発表タイトル:「最小サイクル長が12である空間結合多元QC-LDPC符号に基づくCSS符号の構成」
著者: 河本 大輝(東京科学大学), 笠井 健太(東京科学大学)
詳細は QIT51学生発表賞 受賞者一覧(PDF) をご覧ください。
今後のさらなる活躍が期待されます。おめでとうございます!
論文「Efficient Mitigation of Error Floors in Quantum Error Correction using Non-Binary Low-Density Parity-Check Codes」が、 国際会議 ISIT 2025 に採択されました。
著者: Kenta Kasai(東京科学大学)
本論文では、符号理論的限界に近い性能を持つ量子LDPC符号クラスのエラーフロア性能を向上させる復号アルゴリズムについて議論しています。
論文のプレプリントは arXiv にて公開中です。
最近の研究で使用したソフトウェアおよびパリティ検査行列のデータは、現時点では公開用に整備されておらず、コードも洗練されたものではありません。 それでも構わなければ、妥当なご要望に応じて提供可能です。 ご興味がありましたら、お気軽にご連絡ください。
プレプリント「Breaking the Orthogonality Barrier in Quantum LDPC Codes」 (arXiv:2601.08824) のデモをGitHubで公開しています。
研究・教育の発展のため、奨学寄附金によるご支援をお願いしております。 奨学寄附金は、企業・団体・個人の皆様が本学の事業担当者(教員等)を指定して寄附できる制度で、 いただいたご寄附は教育・研究の奨励等を目的に活用されます。
ご寄附に対しては税制上の優遇措置があります。詳細は大学の案内をご確認ください。
申込方法・詳細: 奨学寄附金について
大学窓口:東京科学大学 研究推進部 産学連携課 産学連携管理グループ
〒152-8550 東京都目黒区大岡山2-12-1 E3-11
TEL: 03-5734-3816 FAX: 03-5734-2482
Mail: don.gra[at]cim.isct.ac.jp([at]を@に変更してください)
Email: kenta@ict.eng.isct.ac.jp
居室: 東京科学大学 大岡山キャンパス南3号館418号室 〒152-8550 東京都目黒区大岡山2-12-1 S3-61