
- Associate Professor, Department of Information and Communications Engineering, Institute of Science Tokyo
- Research Interests: Quantum Error Correction, Coding Theory, Information Theory
Follow me on X
To realize useful quantum computation, it is essential to build a large number of reliable logical qubits. However, the current level of quantum computers is such that even with thousands of physical qubits, only a few tens of logical qubits can be obtained. While this limitation partly stems from engineering constraints such as device implementation and stability, even under an idealized setting of coding theory for quantum error correction, there remain fundamental challenges in code design itself.
Quantum Low-Density Parity-Check (LDPC) codes combined with low-complexity Belief Propagation (BP) decoding have long been regarded as a promising approach. Nevertheless, the following issues have persisted:
To date, no quantum error correction scheme has simultaneously overcome all of these obstacles.
By contrast, the field of classical error correction has already reached maturity. For instance, in mobile communications, LDPC codes have been adopted in the 5G standard, forming the backbone of real-world communication infrastructure. On personal computers as well, large-scale simulations with blocklengths up to \(10^7\) bits are feasible. While classical communication has achieved practical deployment of ultra-large-scale coding, quantum error correction codes are still far from reaching an equivalent level.
We pursue two complementary lines of research in quantum error correction with LDPC codes: binary LDPC-based quantum codes and non-binary LDPC-based quantum codes. Both aim at scalable constructions and practical decoding while pushing performance toward fundamental limits.
In Breaking the Orthogonality Barrier in Quantum LDPC Codes , we focus on the orthogonality constraints between X/Z parity-check matrices, which tend to introduce short cycles and limit code distance and decoding performance. This barrier also means that classical LDPC design principles, such as degree-distribution design, girth control, short-cycle removal, and density-evolution-based BP-threshold optimization, cannot be freely imported into quantum LDPC construction. We control the commutativity of permutation matrices and restrict orthogonality constraints to the “active” part of the construction, while preserving a regular sparse structure. This yields explicit CSS LDPC codes with large girth, avoiding short cycles in the Tanner graph, and aims to recover within qLDPC construction the design freedom developed in classical LDPC coding.
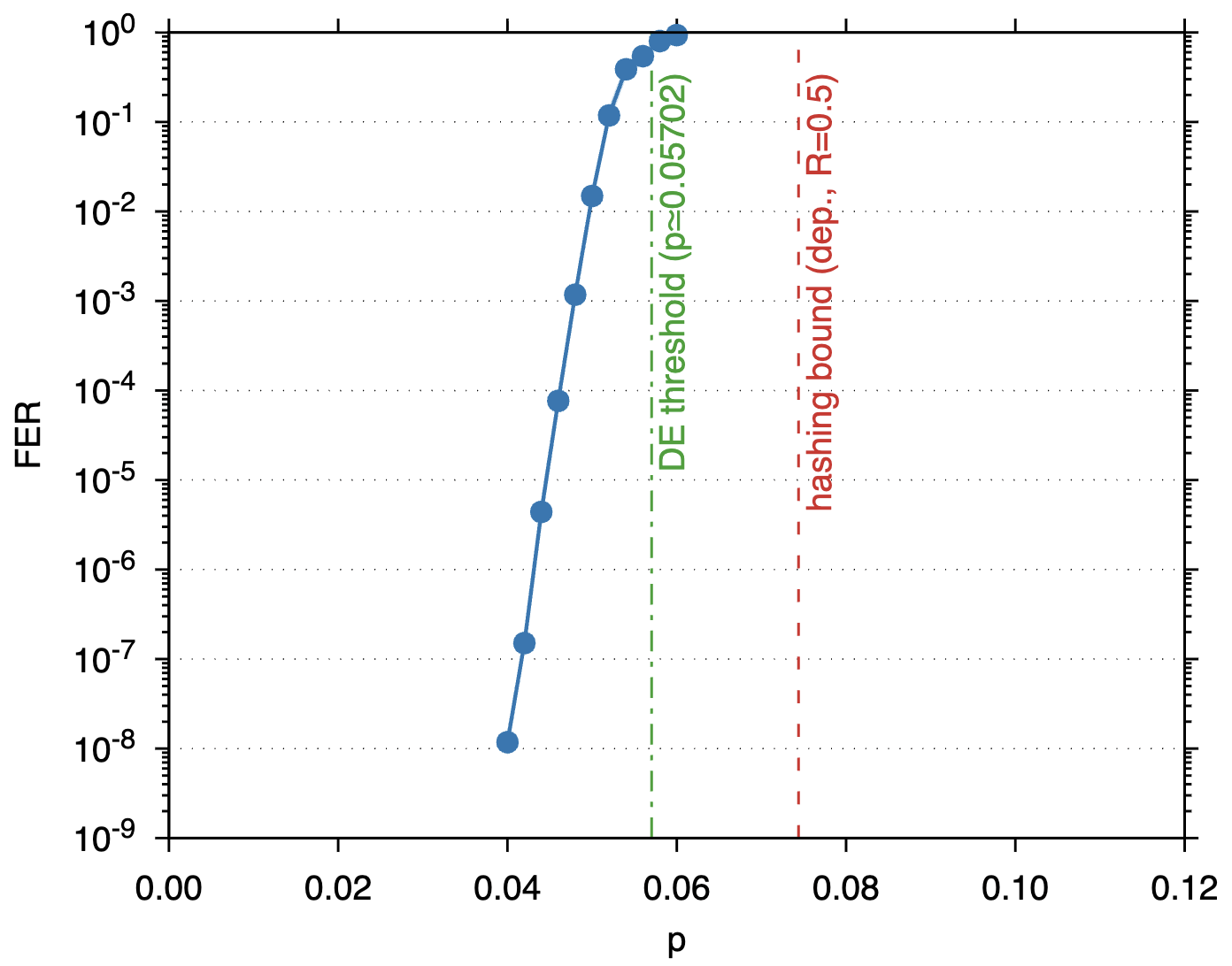
As a concrete demonstration, we construct a girth-8, \((3,12)\)-regular \([[9216,4612, \leq 48]]\) CSS LDPC code and evaluate it under BP decoding combined with low-complexity post-processing on the depolarizing channel. The results show FER \(10^{-8}\) at \(p=4\%\), and density-evolution analysis estimates the decoding threshold at \(p=0.05702\).
Related construction data for A Two-Branch Finite-Field Construction for Regular CSS LDPC Bases are available on a supplementary construction page. The page focuses only on the 64-fold CPM lift of the \(\mathbb F_{16}\) \((3,10)\)-regular base giving a \([[10240,4108,10\le d\le32]]\) CSS code.
Construction data for High-Girth Regular Quantum LDPC Codes from Affine-Coset Structures are available on a supplementary construction page. The page focuses on the P=32 CPM lift of the affine-coset \((3,8)\)-regular base giving a \([[16384,4142,\le40]]\) CSS code.
Construction data for Rate-2/3 Girth-8 (3,18)-Regular Quantum LDPC Codes from Two-Branch Finite-Field Bases and CPM Lifts are available on a supplementary construction page. The page lists the \(\mathbb F_{19}\) two-branch base, the \(P=101\) CPM lift coefficients, verification summaries, forbidden-support data, and distance upper-bound information for the \([[34542,23032,d\le310]]\) CSS code.
Construction data, verification records, and CPM instances for Pair-Partition Constructions for CPM-Based Quantum LDPC Codes are available on a supplementary construction page.
A compact summary of post-processing algorithms after BP decoding, including local repair, OSD-lite, K-OSD, and all-variable syndrome solve, is available as a BP post-processing algorithm note.
Density evolution gives a way to ask a design question before constructing finite-length quantum LDPC codes: which degree distributions should have good belief-propagation (BP) thresholds if the X and Z decoding graphs behaved like random LDPC ensembles with those degree distributions? The calculation shown here is not an asymptotic analysis of a CSS-code ensemble satisfying the orthogonality constraint. It is a coding-theoretic benchmark used to guide which degree distributions are worth trying to realize by explicit CSS constructions.
Density evolution is an analysis method that does not simulate one particular finite-length Tanner graph. Instead, it follows how the probability distribution of BP messages changes from iteration to iteration in the infinite-length limit where the local neighborhood looks like a tree. In a finite graph, cycles and instance-specific structures can affect decoding; density evolution averages those effects away and keeps only the typical message updates determined by the channel error probability, the variable-node degree distribution, and the check-node degree distribution. It should therefore be read as a benchmark for how far BP is expected to work in the idealized infinite-length, tree-like model, not as a proof of the performance of a constructed finite-length CSS code.
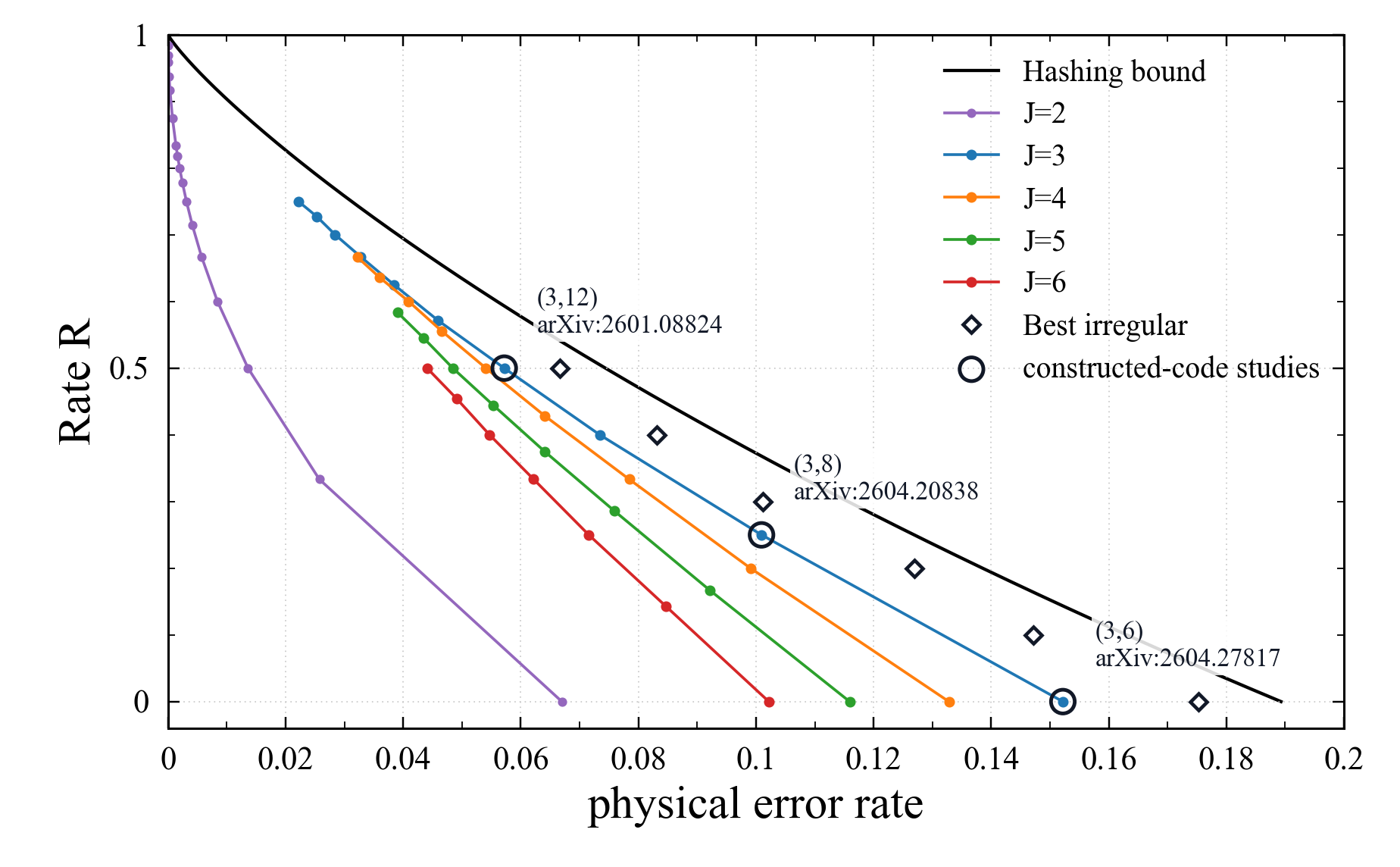
The BP threshold is computed by running population density evolution on an idealized locally tree-like random LDPC-type decoding graph. For each physical error probability \(p\), the population is initialized from the Pauli-error prior induced by the depolarizing channel, and variable-node and check-node updates are iterated according to the chosen degree distribution. If the message distribution converges to the zero-error fixed point, BP is counted as successful; if it remains at a nonzero bad fixed point, BP is counted as unsuccessful. The plotted threshold is estimated by binary search as \[ p_{\mathrm{BP}} = \sup\{p:\text{density evolution converges to the zero-error fixed point}\}. \] For the regular curves, the degree distribution is \((J,L)\)-regular and the design rate is \(R=1-2J/L\). For the black irregular diamonds, the same population-DE procedure is run with the edge-perspective distributions \(\lambda(x)\) and \(\rho(x)\) listed below. Thus the plotted values are BP benchmarks for idealized random LDPC-type models with the same degree distributions, not direct finite-length decoding measurements of constructed CSS codes.
For the \(J=2\) regular series, direct convergence decisions in population DE are numerically delicate. The plotted \(J=2\) values are therefore obtained from the stability boundary rather than from a direct convergence test. The stability necessary condition is \[ \mathfrak{B}(p)\lambda_2\rho'(1)\le 1, \qquad \mathfrak{B}(p)=2\sqrt{\frac{2p}{3}\left(1-\frac{2p}{3}\right)} . \] For a \((J,L)=(2,L)\)-regular ensemble, \(\lambda_2=1\) and \(\rho'(1)=L-1\). Thus the plotted \(J=2\) threshold estimate is the solution of \[ \mathfrak{B}(p_{\mathrm{stab}})(L-1)=1, \qquad p_{\mathrm{stab}}(L)= \frac{3}{4}\left(1-\sqrt{1-\frac{1}{(L-1)^2}}\right), \qquad L=\frac{4}{1-R}. \]
The regular \((3,12)\), \((3,8)\), and \((3,6)\) points are useful reference cases because finite-length experiments already support the corresponding DE predictions. The circled \((3,12)\) point has design rate \(R=1-2\cdot 3/12=0.5\) and DE threshold \(p \simeq 0.05719\). It corresponds to arXiv:2601.08824, where a girth-8, \((3,12)\)-regular \([[9216,4612,\leq 48]]\) code was constructed and tested under BP decoding with post-processing, reaching FER \(10^{-8}\) at physical error rate \(p=0.04\). The circled \((3,8)\) point has design rate \(R=1-2\cdot 3/8=0.25\) and DE threshold \(p \simeq 0.10094\). It corresponds to arXiv:2604.20838, where a CPM-lifted code from a girth-8 \((3,8)\)-regular CSS base code was tested and reached FER about \(10^{-8}\) at physical error rate \(p=0.085\). The circled \((3,6)\) point has design rate \(R=1-2\cdot 3/6=0\) and DE threshold \(p \simeq 0.15219\). It corresponds to arXiv:2604.27817, where a girth-8 \((3,6)\)-regular CSS-LDPC code was tested at physical error rate \(p=0.1402\).
The black diamonds show optimized irregular edge-perspective degree distributions under the design-rate constraint and the standard stability condition, using the same degree distribution on the X and Z sides. These irregular points should be read only as design targets. They are not performance measurements of constructed irregular LDPC-CSS codes, and this plot does not claim that CSS codes with those degree distributions have been constructed. It also does not prove that there is a CSS-code ensemble whose asymptotic BP threshold is given by these points. The question is: if explicit quantum LDPC-CSS constructions can realize these degree distributions and behave similarly under decoding, how much closer can finite-length performance get to the hashing bound? The thresholds for this irregular search were evaluated by population density evolution.
The selected irregular benchmark distributions are listed below in edge perspective as \(\lambda(x)=\sum_i \lambda_i x^{i-1}\) and \(\rho(x)=\sum_j \rho_j x^{j-1}\). The same distributions are used on the X and Z sides, and coefficients are rounded to four decimal places.
| Rate \(R\) | Threshold \(p_{\mathrm{BP}}\) | \(\lambda(x)\) | \(\rho(x)\) |
|---|---|---|---|
| 0.0 | 0.17522 | \(0.2961x+0.2891x^{2}+0.0582x^{7}+0.3362x^{9}+0.0001x^{15}+0.0202x^{31}\) | \(0.0054x^{5}+0.9946x^{6}\) |
| 0.1 | 0.14715 | \(0.1895x+0.2890x^{3}+0.1093x^{5}+0.0937x^{9}+0.1028x^{23}+0.2157x^{31}\) | \(0.1778x^{9}+0.8222x^{10}\) |
| 0.2 | 0.12699 | \(0.1895x+0.2890x^{3}+0.1093x^{5}+0.0937x^{9}+0.1028x^{23}+0.2157x^{31}\) | \(0.8302x^{11}+0.1698x^{12}\) |
| 0.3 | 0.10114 | \(0.0585x+0.3366x^{2}+0.0933x^{3}+0.0097x^{5}+0.2733x^{9}+0.0024x^{23}+0.2261x^{31}\) | \(0.7667x^{13}+0.2333x^{14}\) |
| 0.4 | 0.08311 | \(0.0585x+0.3366x^{2}+0.0933x^{3}+0.0097x^{5}+0.2733x^{9}+0.0024x^{23}+0.2261x^{31}\) | \(0.3941x^{15}+0.6059x^{16}\) |
| 0.5 | 0.06661 | \(0.4969x^{2}+0.4270x^{15}+0.0631x^{23}+0.0130x^{31}\) | \(0.5113x^{19}+0.4887x^{20}\) |
Separately from the BP-decoding threshold, we also use a distance benchmark based on the average weight enumerator of regular LDPC-type ensembles to see how favorable a given degree distribution is from the minimum-distance viewpoint.
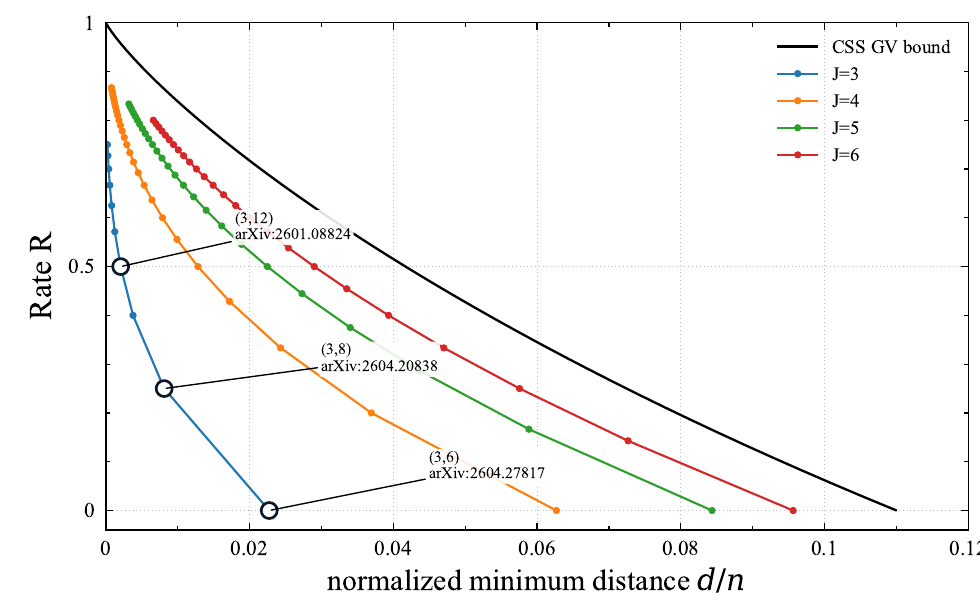
The colored curves are not exact minimum-distance computations for the constructed finite-length CSS codes. They are typical-relative-distance benchmarks obtained from the average weight enumerator of a \((J,L)\)-regular random LDPC-type ensemble. For relative weight \(\delta=d/n\), write the expected number of codewords as \(\mathbb{E}A_{\delta n}\doteq \exp(n\gamma_{J,L}(\delta))\). The plotted distance benchmark for each \((J,L)\) point is the first positive \(\delta\) satisfying \(\gamma_{J,L}(\delta)=0\). Here \[ \gamma_{J,L}(\delta) = h(\delta) +\frac{J}{L}\log P_L(x) -J\delta\log x -J h(\delta), \qquad P_L(x)=\frac{(1+x)^L+(1-x)^L}{2}, \] where \(x\) is the positive saddle-point solution of \[ \frac{xP_L'(x)}{P_L(x)}=L\delta . \] The curve for a fixed \(J\) is obtained by varying \(L\) and plotting the CSS design rate \(R=1-2J/L\). The black CSS GV curve is \(R=1-2h_2(\delta)\).
Upper-bound definitions are summarized here. The accompanying manuscript is arXiv:2604.15307.
The parameter files themselves are linked from the code entries below. See
this short guide for how to read those files, and
this note on upper-bound constructions for formal definitions of
Latent UB, m-block UB, Fiber-quotient UB, CRT UB,
Cycle-8 ETS UB, Direct CSS UB, and Decoder-fail UB.
The m-block UB column records the full-fiber block-compression case, while
Fiber-quotient UB records proper selected-fiber patterns only; the two columns
are therefore separated method-specific entries, not a single minimized fiber-pattern value.
A consolidated supplementary page for this project is available here.
These exploratory rows use girth at least 6 and enforce the two noncommuting pairs \((0,3)\) and \((1,2)\). They are kept separate from the girth-8 table below. The lower bound \(d \geq 8\) comes from an exact low-weight screening: odd weights are excluded by column weight 3, weight 2 is excluded by the girth condition, and weights 4 and 6 were not found in either CSS kernel. The decoder-fail upper bound also includes nondegenerate logical residuals observed during the FER runs.
A 3-Mac follow-up for smaller \(P\) found candidates at \(P=28,36,42,48\), but each was removed by a weight-6 logical witness. Rows whose upper-bound evidence already fixes \(d=8\) are omitted from this exploratory list; the current smallest listed row is \(P=92\). The exclusion summary is available as TSV. The \(P=192\) S1--S4 rows are the four survivor family members from the Toward-style P192 search.
| \(P\) | Current best code | Latent UB | \(m\)-block UB | Fiber-quotient UB | CRT UB | Cycle-8 ETS UB | Direct CSS UB | Decoder-fail UB | DFC trials | FER Plot | Seed |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 96 | \(\left[\left[1152,580,8\leq d\leq 10\right]\right]\) | 36 | 32 | 24 | 54 | -- | 32 | 10 | 105.39M |  CSVerrors CSVerrors |
960590001 |
| 120 | \(\left[\left[1440,724,8\leq d\leq 12\right]\right]\) | 48 | 24 | 24 | 30 | -- | 30 | 12 | 6.00M |  CSV CSV |
1203320015 |
| 140 S1 | \(\left[\left[1680,844,8\leq d\leq 14\right]\right]\) | 24 | 28 | 20 | 20 | -- | 56 | 14 | 37,813,026+ |  CSV CSV |
1405120011 |
| 192 S1 | \(\left[\left[2304,1156,8\leq d\leq 16\right]\right]\) | 36 | 32 | 24 | 24 | -- | 128 | 16 | 10844.21M |  CSVerrors CSVerrors |
1924120265 |
| 192 S2 | \(\left[\left[2304,1156,8\leq d\leq 16\right]\right]\) | 36 | 32 | 24 | 72 | -- | 64 | 16 | 5981.19M |  CSVerrors CSVerrors |
1924120041 |
| 192 S3 | \(\left[\left[2304,1156,8\leq d\leq 16\right]\right]\) | 36 | 16 | 16 | 120 | -- | 74 | 16 | 5751.39M |  CSVerrors CSVerrors |
1924168100 |
| 192 S4 | \(\left[\left[2304,1156,8\leq d\leq 16\right]\right]\) | 36 | 32 | 24 | 102 | -- | 126 | 16 | 9499.30M |  CSVerrors CSVerrors |
1924160123 |
Rows are sorted by increasing \(P\). Each listed girth-6 row passed an exhaustive weight-4 and weight-6 syndrome-zero screen on both CSS sides; odd weights up to 7 are impossible because each column has weight 3. Rows with a confirmed \(d<8\) witness are omitted.
| \(P\) | Current best code | Latent UB | \(m\)-block UB | Fiber-quotient UB | CRT UB | Cycle-8 ETS UB | Direct CSS UB | Decoder-fail UB | DFC trials | FER Plot | Seed |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 240 | \(\left[\left[2880,1444,10\leq d\leq 24\right]\right]\) d>=10 screen |
24 | 40 | 24 | 40 | NE | 40 | 24 | 97.10M |  CSVerrors CSVerrors |
2404844464 |
| 264 | \(\left[\left[3168,1588,\leq 22\right]\right]\) | 24 | 44 | 44 | 44 | NE | 44 | 22 | 128.00M | 275023 |
|
| 288 | \(\left[\left[3456,1732,\leq 24\right]\right]\) | 24 | 24 | 24 | 64 | NF | 32 | 28 | >448.00M | 17230036422081291 |
|
| 384 | \(\left[\left[4608,2308,\leq 24\right]\right]\) | 24 | 48 | 48 | 204 | NE | 128 | 28 | 84.00M | 17229885754182916 |
|
| 384 (candidate) | \(\left[\left[4608,2308,\leq 48\right]\right]\) | 48 | 48 | 64 | 54 | NE | 64 | -- | 314.47M | 3842304791 |
|
| 576 | \(\left[\left[6912,3460,\leq 32\right]\right]\) | 48 | 64 | 32 | 72 | NF | 72 | -- | 49.81M | 17646913617314833 |
|
| 768 | \(\left[\left[9216,4612,\leq 48\right]\right]\) | 48 | 108 | 64 | 222 | NF | 74 | -- | 102.24M | 17592239305062458 |
|
| 768 (paper code) | \(\left[\left[9216,4612,\leq 24\right]\right]\) | 48 | 32 | 24 | 96 | NE | 128 | -- | 40.00M | paper |
|
| 1536 | \(\left[\left[18432,9220,\leq 48\right]\right]\) | 48 | 256 | 96 | 978 | NF | 512 | -- | 86.05M | 17613728482828666 |
|
| 1536 (candidate) | \(\left[\left[18432,9220,\leq 48\right]\right]\) | 192 | 96 | 48 | 996 | NE | 512 | -- | 18.05M | 1536612105 |
|
| 1920 | \(\left[\left[23040,11524,\leq 64\right]\right]\) | 120 | 64 | 64 | 96 | NF | 96 | -- | 88.45M | 17622415249116583 |
|
| 1920 (candidate) | \(\left[\left[23040,11524,\leq 192\right]\right]\) | 240 | 256 | 192 | 256 | NE | 256 | -- | 12.45M | 1920612082 |
|
| 2688 | \(\left[\left[32256,16132,\leq 128\right]\right]\) | 336 | 128 | 128 | 224 | NE | 224 | -- | 76.98M | 2688047043 |
|
| 3072 | \(\left[\left[36864,18436,\leq 96\right]\right]\) | 96 | 192 | 192 | 2048 | NF | 640 | -- | 4.00M | 17613741499129833 |
|
| 3840 | \(\left[\left[46080,23044,\leq 128\right]\right]\) | 480 | 128 | 128 | 240 | NF | 240 | -- | 4.00M | 17622378158439083 |
|
| 3840 (candidate) | \(\left[\left[46080,23044,\leq 160\right]\right]\) | 480 | 256 | 160 | 512 | NE | 256 | -- | 5.28M | 3840356020 |
This table records upper bounds obtained from witnesses checked by the mechanisms named in the column headers.
In the Cycle-8 ETS UB column, NF means that the recorded evaluation produced no CSS witness,
whereas NE means that no evaluation is recorded for that row. Neither label should be read as an
exhaustive proof of nonexistence.
In the DFC trials column, -- means that no decoder-failure trial count is recorded for that row.
In our npj Quantum Information paper , we develop non-binary LDPC-CSS constructions and decoding methods that leverage larger field alphabets. The goal is to achieve strong finite-length performance with practical decoding complexity, especially in the low-FER (error-floor) regime relevant to reliable quantum information processing.
Our decoding approach incorporates belief-propagation variants adapted to non-binary structures and explores post-processing strategies that account for degeneracy. The study reports performance close to the hashing bound under practical decoding, highlighting the promise of non-binary LDPC codes for scalable quantum error correction.
This section collects publicly available software, data archives, and supplementary materials related to our recent papers.
In the prefix_value files, the numbers
\(1,2,\ldots,255\) represent
\(\alpha^0,\alpha^1,\ldots,\alpha^{254}\) for a primitive element
\(\alpha\). The primitive polynomial can be found in the corresponding
paper.
For other software or data related to these papers, please feel free to contact us.
A: The commutativity condition \(H_X H_Z^{T} = 0\) is essential, but enforcing it directly at the level of sparse regular binary parity-check matrices severely restricts edge placements. This tends to introduce many short cycles (especially 4- and 6-cycles), which reduces girth and hurts distance and BP performance. We refer to this obstruction as the orthogonality barrier.
In a broader sense, the orthogonality barrier is also the reason why design principles from classical LDPC coding could not be imported freely into quantum LDPC code design. In classical LDPC codes, one can combine degree-distribution design, girth control, short-cycle removal, and density-evolution-based BP-threshold optimization with considerable freedom. In CSS codes, however, \(H_X\) and \(H_Z\) must be orthogonal. Improving one Tanner graph may break commutativity with the other, while enforcing orthogonality too directly can create short cycles or low-weight harmful structures. This is why classical LDPC design ideas could not simply be reused as they were.
In our framework, the construction uses latent matrices that provide design freedom together with parent matrices, and orthogonality is enforced only on the active matrices (not on the parent matrices themselves). By controlling commutativity on the active part, we retain regularity while avoiding short cycles and achieving larger girth. This lets us bring classical-LDPC-style design freedom, such as girth control and degree-distribution design, into quantum LDPC construction while still satisfying orthogonality. Thus “breaking the orthogonality barrier” means more than constructing one commuting code: it means recovering, inside qLDPC design, the classical coding design principles that had been blocked by the orthogonality constraint.
Reference: arXiv:2601.08824
A: This is a very reasonable concern. At very long block lengths, it is often difficult to obtain solid lower bounds, and relying only on upper bounds can make it hard to judge how much the construction helps. Shorter instances would make it easier to compute convincing lower bounds and verify whether the distance is genuinely improved.
The latest arXiv version includes a brief discussion of an idea to relax some construction constraints to target shorter block lengths while aiming to keep girth 8 and (hopefully) minimum distance 48: arXiv:2601.08824.
Reference: arXiv:2601.08824
A: Avoiding only 4-cycles is not sufficient to unlock strong BP performance, so we also eliminate 6-cycles. As discussed in arXiv:2601.08824, in generalized Hagiwara-Imai codes with column weight \(\ge 3\), 8-cycles cannot be avoided, so girth 8 is the practical target in our setting.
Reference: K. Kasai, “Breaking the Orthogonality Barrier in Quantum LDPC Codes,” arXiv:2601.08824, 2026
A: In density-evolution benchmarks, column weight 3 is the best-performing choice. Row weight 12 is the smallest value achievable by our proposed construction, so \((3,12)\)-regular is a natural design point.
Reference: arXiv:2601.08824
Looking only at the row weight can be misleading, because BP decoding performance is not determined by row weight alone. In the \((3,12)\)-regular design, the column weight is kept at 3, so the local information flow around variable nodes remains favorable. Moreover, by eliminating 4-cycles and 6-cycles and targeting girth 8, the early BP messages are closer to the tree-like behavior assumed by density evolution. In other words, in the ideal-syndrome model, the waterfall performance is governed primarily by the DE threshold together with finite-length effects.
Row weight 12 is large in the sense that each check node touches many variables, but it is also the design point that realizes rate \(R=1-2\cdot3/12=1/2\). Keeping a high rate requires fewer checks relative to the number of variables, which naturally increases the row weight. The key is not merely to lower the row weight, but to control the placement so that the larger checks do not create many short cycles or harmful low-weight structures.
The decoder also matters. The joint BP decoder used in the experiments does not decode the \(X\) and \(Z\) components independently; it preserves the local correlation of Pauli errors at each qubit. Residual trapping-cycle errors are then corrected by lightweight post-processing. Thus the observed performance comes from the combination of girth, degree distribution, correlation-preserving decoding, and post-processing.
Of course, row weight 12 is also a disadvantage for syndrome-extraction circuits. A high-weight check touches many qubits, so measurement faults and circuit faults can accumulate and increase the effective noise seen by the decoder. The current interpretation is that the \((3,12)\)-regular LDPC code has sufficiently strong ideal-decoding performance, as predicted by DE and observed with joint BP, to more than compensate for this disadvantage in the regimes studied. Therefore, a circuit-level evaluation must balance the extra noise caused by larger checks against the stronger decoding capability of the code itself.
Reference: arXiv:2601.08824, arXiv:2605.05132
No. Classical LDPC theory provides powerful design principles, such as degree distributions, girth, density evolution, and minimum-distance heuristics, but quantum error correction has additional constraints. A quantum CSS code must satisfy the orthogonality condition \(H_XH_Z^{\mathsf T}=0\). It must also support syndrome-extraction circuits, tolerate measurement errors, solve a space-time decoding problem involving both data and measurement faults, and fit the interaction structure available on the target hardware.
Thus the goal is not to transplant a classical LDPC construction unchanged into the quantum setting. The useful strategy is to start from the good local structure and BP-threshold intuition of classical LDPC codes, and then redesign the code around CSS orthogonality, avoidance of low-weight logical operators, decoder structure, implementable syndrome extraction, and performance under circuit-level noise. In this sense, classical coding theory is an important benchmark, but practical qLDPC design is a different co-design problem involving the code, the implementation, and the decoder.
For example, arXiv:2601.08824 aims to keep classical-LDPC-like large-girth structure while handling CSS orthogonality and avoiding harmful low-weight structures. In arXiv:2604.16209, the design is evaluated in a more implementation-oriented setting, including syndrome extraction on reconfigurable atom arrays, atom-rearrangement constraints, a hierarchical decoder, and a circuit-level noise model. The basic philosophy is therefore to use the strengths of classical LDPC design, while adapting the code to the circuit, noise, and decoding constraints required for quantum computation.
A: The baseline decoder is joint belief propagation (joint BP). CSS syndrome decoding is written as a factor graph in which the \(X\)- and \(Z\)-side Tanner graphs are coupled by the local joint prior at each qubit, and the sum-product algorithm is run on this factorization. This lets BP retain the local correlation between the two Pauli error components instead of decoding them separately.
In the experiments, this joint BP decoder is combined with lightweight post-processing. In particular, we apply PP-flip and PP-OSD to correct residual trapping-cycle errors, improving the low-FER regime without heavy complexity.
Reference: arXiv:2601.08824, arXiv:2605.05132
A: The “\(\le 48\)” indicates an upper bound on the minimum distance. This bound is derived from a potential (latent) matrix associated with the construction. Obtaining convincing lower bounds—especially at very long block lengths—is challenging and is a key motivation for exploring shorter instances.
Reference: arXiv:2601.08824, arXiv:2604.15307
A: Density evolution tracks the message distributions of BP under the cycle-free (tree) assumption in the infinite-length limit. The threshold is the crossover point where BP transitions from successful to unsuccessful decoding on average. It serves as an analytical benchmark, not a finite-length guarantee.
Reference: arXiv:2601.08824
A CSS-type non-orthogonal code ensemble means an idealized ensemble with two LDPC-type parity-check matrices, one for the \(X\) side and one for the \(Z\) side, but without yet imposing the CSS orthogonality condition \(H_XH_Z^{\mathsf T}=0\). Density evolution treats this non-orthogonal ensemble as a classical-LDPC-like tree model and tracks how the BP message distribution evolves in the infinite-length limit.
In practice, the message distribution is often too complicated to write in closed form, so we use Monte Carlo density evolution, also called population density evolution. The idea is to represent the message distribution by a large population of samples and repeatedly apply variable-node, check-node, and channel updates by random sampling.
The important point is that this is a benchmark, not a performance guarantee for a constructed finite-length CSS code. Orthogonality, short cycles, finite-length effects, degeneracy, and correlations between the \(X\) and \(Z\) sides are outside this idealized model. Thus the DE threshold is used as a reference for what BP performance one would expect from a classical-LDPC-like ideal model with the same degree distribution.
Comparing this benchmark with simulations of an explicitly constructed orthogonal CSS code tells us how much of the classical LDPC iterative-decoding behavior is preserved after imposing the CSS orthogonality constraint.
Reference: D. Divsalar, S. Dolinar, C. Jones, and K. Andrews, “Capacity-Approaching Protograph Codes,” IEEE J. Sel. Areas Commun., 2009, T. Richardson and R. Urbanke, Modern Coding Theory, Chs. 3--5 and App. B, 2008
If density evolution is a benchmark for BP decoding performance, minimum-distance analysis is a benchmark for how often low-weight codewords appear in a classical-LDPC-like ideal ensemble with the same degree distribution. In the CSS-type non-orthogonal model, the \(X\)- and \(Z\)-side parity-check matrices are first treated as separate classical LDPC parity-check matrices, and one studies the expected number of low-weight vectors in their kernels or the growth rate of their weight distributions.
A typical calculation estimates the exponential growth rate of the expected number of vectors of weight \(\omega n\) satisfying the parity checks. If this growth rate is negative in a weight range, vectors of that weight are unlikely to appear in the random ensemble. This gives a classical-LDPC-style indication of whether the minimum distance should grow linearly, or whether low-weight structures are expected to be common.
This is not, however, a proof of the minimum distance of a constructed finite-length quantum CSS code. The actual CSS distance is affected by the orthogonality condition \(H_XH_Z^{\mathsf T}=0\), equivalence modulo row spaces, degeneracy, finite-length short cycles, and special algebraic structure. Therefore this analysis should be read as a benchmark for the classical-LDPC-like distance behavior before imposing the CSS orthogonality constraint.
Comparing this benchmark with low-weight searches and upper/lower-bound calculations for an explicitly constructed orthogonal CSS code helps measure how much the orthogonality constraint and the construction rules create low-weight logical operators.
Reference: R. G. Gallager, “Low-Density Parity-Check Codes,” IRE Trans. Inf. Theory, 1962, S. Abu-Surra, D. Divsalar, and W. E. Ryan, “Enumerators for Protograph-Based Ensembles of LDPC and Generalized LDPC Codes,” IEEE Trans. Inf. Theory, 2011, T. Richardson and R. Urbanke, Modern Coding Theory, Ch. 7, 2008
This is a natural concern. Since LDPC constructions contain randomness, one has to ask whether a particular instance might deviate substantially from the ensemble-average behavior. In classical LDPC coding theory, concentration theorems address exactly this issue for standard ensembles specified essentially by the degree distribution: for sufficiently large blocklength, the BP decoding performance of a random LDPC code concentrates with high probability around the average behavior predicted by density evolution.
Our CSS construction includes orthogonality constraints and algebraic placements, so the concentration theorem in Modern Coding Theory does not apply to it directly. In the actual design, we also impose constraints beyond the degree distribution, such as girth, blocklength, and upper-bound checks related to the minimum distance. Nevertheless, empirically, after these constraints are imposed, random choices from the remaining degrees of freedom still show the same kind of self-averaging behavior familiar from classical LDPC ensembles: different instances with the same design parameters tend to have similar decoding behavior.
Empirically, this is what we observe. When several instances with the same design parameters are compared, their FER curves and BP waterfall locations tend to cluster in a similar range close to the density-evolution benchmark, rather than showing wildly different behavior. The error-floor region needs more care, however. The failure-rate scale of practical interest is extremely small, so it is more sensitive to rare harmful structures and finite-length effects than the waterfall region. Thus the current interpretation is that the proposed construction appears to exhibit concentration-like behavior for waterfall performance, while a rigorous concentration theorem including the CSS orthogonality constraint and a full error-floor analysis remain open theoretical problems.
Reference: T. Richardson and R. Urbanke, Modern Coding Theory, Ch. 3 and App. C, 2008, arXiv:2601.08824
A: One characteristic feature is that we try to inject as much randomness as possible into the construction. More precisely, within the class of codes satisfying the required regularity and girth constraints, we try to construct codes as randomly as possible. Fully unconstrained randomness is incompatible with CSS commutativity and large girth, so the guiding principle is to impose only the necessary constraints and keep the construction otherwise as unbiased as possible.
Reference: arXiv:2601.08824
We do not generate completely unconstrained random codes. Instead, we first specify the code ensemble we want to sample from. The constraints include the degree distribution, girth, blocklength, CSS orthogonality, and checks related to low-weight structures. Since it is difficult to certify the exact minimum distance at very large blocklengths, we use low-weight logical-operator searches and upper-bound evaluations to screen candidate instances.
Within the set of candidates satisfying these constraints, we then choose shifts, APM elements, finite-field coefficients, and related construction data randomly. In other words, the construction does not fix a single deterministic code from the outset; it randomly selects a code instance from the constrained ensemble of codes satisfying regularity, large girth, orthogonality, and distance-related screening criteria.
This is how randomness is injected while preserving the constraints required for a quantum CSS code. The goal is to retain as much of the randomness and self-averaging behavior familiar from classical LDPC ensembles as possible, without giving up CSS commutativity.
Reference: arXiv:2601.08824
The construction cleverly exploits two well-known insights from classical coding theory: (i) non-binary LDPC codes with column weight two tend to perform especially well under iterative decoding, and (ii) column weight two allows flexible designs that can effectively eliminate short cycles in the Tanner graph.
By combining these properties with affine permutation matrix (APM) placements, the proposed codes achieve both orthogonality and large girth, which suppress error floors and enable sharp threshold-like performance. As a result, the quantum LDPC codes constructed in this way approach the hashing bound, even at practical blocklengths.
Reference: arXiv:2506.15636, arXiv:2501.13923
A binary parity-check matrix with column weight 2 can be viewed as the incidence matrix of an ordinary graph: each variable node is an edge connecting the two check nodes in which that column has ones. A codeword is then a set of edges for which every check node has even degree, namely a sum of cycles. Therefore, the minimum distance is upper bounded by the length of the shortest cycle in that graph.
Since LDPC codes also have bounded row weight, the corresponding graph has bounded degree. In bounded-degree graphs, the shortest cycle length can grow at most on the order of \(\log n\) as the number of vertices grows. Thus binary column-weight-2 LDPC codes cannot be expected to have minimum distance growing linearly with blocklength.
Reference: R. G. Gallager, “Low-Density Parity-Check Codes,” IRE Trans. Inf. Theory, 1962, T. Richardson and R. Urbanke, Modern Coding Theory, Chs. 2 and 7, 2008
The reason is already visible from density evolution on the binary erasure channel. For a \((d_v,d_c)\)-regular LDPC ensemble over the BEC, let \(\epsilon\) be the channel erasure probability and let \(x_l\) be the erasure probability of a variable-to-check message at iteration \(l\). The density-evolution update is \[ x_{l+1} = \epsilon\left(1-(1-x_l)^{d_c-1}\right)^{d_v-1}. \]
For column weight 2, namely \(d_v=2\), this becomes \[ x_{l+1} = \epsilon\left(1-(1-x_l)^{d_c-1}\right) = \epsilon(d_c-1)x_l+O(x_l^2). \] Thus the slope near the zero fixed point is \(\epsilon(d_c-1)\). Successful BP decoding requires the zero fixed point to be stable, so one must have \(\epsilon(d_c-1)<1\), or equivalently \(\epsilon<1/(d_c-1)\).
This is the binary-LDPC picture. If the same column-weight-2 structure is lifted to a non-binary finite field, each BP message becomes a probability distribution over field elements rather than a single binary reliability value. This gives the decoder more information to work with, and in high-rate regimes column-weight-2 non-binary LDPC codes can perform much better than their binary counterparts. The npj Quantum Information paper uses this finite-field extension idea together with the CSS construction, retaining the structural advantages of column weight 2 while obtaining strong decoding performance.
In the binary case, this upper bound becomes especially small in the high-rate regime, where the row weight \(d_c\) is large. By contrast, for column weight 3 or larger, the linear term near zero disappears, so this first-order stability constraint does not arise in the same way. This is the basic reason why regular binary LDPC codes with column weight 2 tend to have poor BP thresholds, while non-binary extensions can substantially improve performance.
Reference: R. G. Gallager, “Low-Density Parity-Check Codes,” IRE Trans. Inf. Theory, 1962, T. Richardson and R. Urbanke, Modern Coding Theory, Ch. 3, Sec. 3.9, and App. B, 2008, D. Komoto and K. Kasai, “Quantum error correction near the coding theoretical bound,” npj Quantum Information, 2025
Indeed, classical binary LDPC codes with column weight 2 have a minimum distance that grows only logarithmically with respect to the code length, and their BP decoding threshold is significantly worse than that of column-3 codes. However, the situation is quite different for non-binary LDPC codes. When the code rate is high, the BP threshold of column-2 non-binary LDPC codes can approach the channel capacity, whereas that of column-3 codes becomes much poorer.
Moreover, non-binary extensions can substantially increase the minimum distance, leading to performance without observable error floors. As mentioned in the following Q&A, it is well known in classical coding theory that good BP decoding performance does not necessarily require the minimum distance to grow linearly with the code length.
Reference: Roumy et al., 2004, Jin, Khandekar, and McEliece, 2000, arXiv:2506.15636
The minimum distance of our codes does not grow linearly with blocklength. However, this does not prevent strong decoding performance under belief propagation (BP). From the theory of density evolution, it is well understood that what primarily determines BP performance are the column weight and row weight of the parity-check matrix, not the asymptotic growth of minimum distance.
Furthermore, it is known that classical LDPC codes with column weight three or larger typically have minimum distance that grows linearly with blocklength when constructed at random. This explains why researchers in LDPC coding theory tend not to emphasize minimum distance as the decisive factor: good iterative decoding performance can be achieved without relying on very large minimum distance.
While minimum distance is an important metric for characterizing the error-floor regime, achieving linearly growing minimum distance is not strictly necessary for excellent iterative decoding performance. This insight can be traced back to lessons from classical coding theory. During the 1980s and early 1990s, much of the community’s attention was directed toward the algebraic aspects of minimum-distance theory, and practical iterative methods received less focus. Consequently, the (re)discovery of turbo codes (1993) and LDPC codes (reintroduced in the mid-1990s, following Gallager’s original 1962 work) came somewhat later, even though their effectiveness derives not primarily from large minimum distance but from efficient iterative decoding and code structures that are well suited for BP.
Reference: arXiv:2506.15636
The framework integrates four ingredients:
(i) Affine permutation matrix (APM) constructions to avoid short cycles,
(ii) joint belief propagation decoding over non-binary fields \(\mathbb{F}_q\),
(iii) optimization of minimum distance by carefully selecting matrix entries,
(iv) lightweight post-processing to remove residual errors.
Reference: arXiv:2506.15636, arXiv:2501.13923
Conventional BP decoding for CSS codes often treats \(X\) and \(Z\) errors as two separate binary LDPC decoding problems. Under depolarizing noise, however, the two Pauli components on the same qubit are not independent: they are locally correlated through \(Y\) errors. The proposed joint BP builds a factor graph in which the \(X\)-side and \(Z\)-side Tanner graphs are coupled by the local joint prior at each qubit, and then runs the sum-product algorithm on that factorization. The main difference is that syndrome decoding is performed without discarding the local correlation between the two Pauli error components.
Another equivalent viewpoint is four-state BP, where the local states are the Pauli labels \(I,X,Y,Z\). arXiv:2605.05132 shows that joint BP and four-state BP compute the same posterior weights, messages, and beliefs after relabeling the four local Pauli states and marginalizing the irrelevant binary component. In this sense, joint BP is a CSS-explicit binary factor-graph formulation: it preserves the correlation lost by separate \(X/Z\) decoding while representing the same essential posterior calculation as four-state BP.
The stabilizer weight is upper bounded by e × L, where e is the field extension degree and L is the row weight. For example, with e = 8 and L = 6, the stabilizer weight is at most 48, and crucially remains constant regardless of code length.
Reference: arXiv:2506.15636
No. Although matrices are defined over \( \mathbb{F}_q \) and decoding operates over non-binary fields, the physical system is still qubits. Each element of \( \mathbb{F}_q \) is expanded into an \( e \times e \) binary companion matrix, ensuring the code remains a binary CSS code.
Reference: arXiv:2506.15636
Our method generalizes the Hagiwara–Imai construction. Specifically, we place affine permutation matrices (APMs) at cyclically shifted positions within the parity-check matrices. By carefully choosing the shifts and the APM entries, the resulting non-binary matrices \( H_{\Gamma} \) and \( H_{\Delta} \) become orthogonal over \( \mathbb{F}_q \).
In other words, the inner product between any row of \( H_{\Gamma} \) and any row of \( H_{\Delta} \) cancels to zero in \( \mathbb{F}_q \). After expanding each field element into an \( e \times e \) binary companion matrix, we obtain binary parity-check matrices \( H_X \) and \( H_Z \) that satisfy \( H_X H_Z^{T} = 0 \). This approach ensures orthogonality while avoiding short cycles, leading to improved decoding performance.
Reference: arXiv:2506.15636
A natural intermediate choice is the one-dimensional affine group \( \mathrm{AGL}_1(R)=R\rtimes R^{\times} \) over a finite ring \(R\). It is richer than pure generalized permutation/monomial actions because it includes translations as well as multiplicative actions, but it is still structured enough to analyze algebraically and to use in explicit code constructions.
In particular, affine groups over finite commutative principal ideal rings provide a good balance between flexibility and tractability. They are noncommutative in an essential way, yet remain close enough to permutation-matrix-based constructions to be useful for QLDPC design.
Reference: arXiv:2604.02063
No. The density-evolution conclusion is an ensemble-level asymptotic statement, not a rule forbidding every individual degree-2 column. A small number of degree-2 columns can be acceptable, and in irregular LDPC design they are often used deliberately.
The real issue is whether degree-2 columns appear with too large a fraction or in harmful local configurations that create long chains, small stopping sets, or trapping sets. So the right design principle is not “never use degree 2,” but rather “control carefully how much degree 2 is used and where it appears.”
Reference: Roumy et al., 2004, Jin, Khandekar, and McEliece, 2000
When the decoding performance of an LDPC code is plotted with the channel error probability on the horizontal axis and FER or BER on a logarithmic vertical axis, the curve typically has two qualitatively different regions. Near the threshold, a small improvement in the channel error probability can cause the decoding-failure probability to drop very rapidly. This steep transition is called the waterfall region. For BP decoding, the location and shape of this region are closely related to the density-evolution threshold and to finite-length scaling.
In the waterfall region, the main failure mechanism is the existence of nontrivial fixed points of the density-evolution equations, together with finite-length fluctuations that push the decoding trajectory to the bad side. As a result, BP can leave behind errors whose size scales proportionally with the code length.
As the channel error probability is reduced further, the curve may stop dropping steeply and begin to flatten. This is the error-floor region. In this regime, the dominant mechanisms are no longer the average density-evolution behavior, but rare local structures such as low-weight logical operators related to the minimum distance, or small trapping sets that negatively affect BP convergence. The remaining error size is usually of order \(O(1)\), namely it does not scale with the blocklength. Thus good waterfall performance and the absence of an error floor down to very small FER are related, but they are distinct design goals.
Reference: arXiv:2501.13923, arXiv:2506.15636
For LDPC codes on the binary erasure channel, finite-length scaling in the waterfall region is fairly well understood. Near the density-evolution threshold \(p_{\mathrm{th}}\), decoding success is governed mainly by whether finite-length randomness shifts the effective threshold to one side or the other. This fluctuation is a sum of many local contributions, so it is naturally approximated by a Gaussian law.
As a result, for blocklength \(n\) and physical error rate \(p\), the failure probability has the schematic form \[ P_{\mathrm{fail}}(p,n) \approx Q\!\left(\frac{p_{\mathrm{th}}-p}{\alpha n^{-1/2}}\right), \] where \(Q(x)\) is the upper tail of the standard normal distribution. In other words, the sharp asymptotic threshold is rounded at finite length over a window of width \(O(n^{-1/2})\), and the rounded transition is described by a Gaussian tail.
The rigorous theory is clearest for the binary erasure channel, but similar finite-length scaling is often observed empirically for more general iterative decoders. This is why fitting BP FER curves by a Q-function is a natural way to summarize waterfall-region finite-length effects.
Conventional quantum LDPC codes suffer from low coding rates, high error floors, lack of scalability, and heavy post-processing requirements. As a result, performance does not scale with blocklength and remains far from the hashing bound. Our work aims to construct codes with non-vanishing rate and efficient decoding that achieve performance close to the hashing bound.
Reference: arXiv:2601.08824, arXiv:2506.15636
Threshold phenomena and error-floor behavior become visible only at very large blocklengths. Demonstrating sharp threshold-like performance without error floors in this regime provides the strongest evidence of scalability. While short blocklengths also show good scaling, long blocklength results best highlight the theory.
Reference: arXiv:2601.08824, arXiv:2506.15636
No. The analysis assumes an idealized setting where all gate operations, stabilizer measurements, and recovery operations are error-free. The purpose is to isolate the coding-theoretic limitations apart from engineering constraints.
In contrast, arXiv:2604.16209 studies a more implementation-oriented setting for reconfigurable atom arrays, including syndrome extraction, atom rearrangement constraints, and a circuit-level noise model. Thus the ideal-measurement model discussed here should be understood as a coding-theoretic benchmark, while circuit-level noise is treated in that related work.
Reference: arXiv:2601.08824, arXiv:2506.15636, arXiv:2604.16209
Decoding is judged by whether the difference between the true error and the estimated error belongs to the dual code. In other words, if \( (x + \hat{x}) \in C_X^{\perp} \) and \( (z + \hat{z}) \in C_Z^{\perp} \), then the decoding is considered successful, because both correspond to valid stabilizers and represent the same logical state.
If the difference vector is not in the dual, then the estimated error introduces a logical error and decoding is considered unsuccessful. Our framework also includes lightweight post-processing that can correct many failures by resolving small trapping-cycle structures.
Reference: arXiv:2506.15636, arXiv:2601.08824
In our framework, decoding success is not judged merely by reproducing the measured syndrome. Instead, the definition is stricter: the difference between the true error and the estimated error must belong to the dual code. In that case, the estimated error corresponds to a valid stabilizer and preserves the logical state, and only then is decoding counted as successful. If this condition is not met, the event is classified as a decoding failure since it introduces a logical error.
For further questions not covered here, please contact us directly via the Contact section below.
In this year's papers arXiv:2601.08824 and arXiv:2604.20838, we exhibited concrete (3,*)-regular quantum LDPC families, including (3,12)-regular, (3,8)-regular, and (3,6)-regular examples, with large girth constructions and strong decoding performance. In arXiv:2511.04634, we also attempted a random construction method for qLDPC codes, but it did not succeed in systematically producing large girth. On the other hand, the constructed (3,*)-regular families sometimes show experimentally strong performance close to DE benchmarks, but there is still no general theorem guaranteeing this behavior. In addition, arXiv:2604.15307 presents many explicit upper-bound witnesses for the minimum distance of quantum APM-LDPC codes, including these families. However, a unified theory explaining why these constructions work well is still missing.
Please get in touch if you are interested in this group of problems.
In arXiv:2603.24588, we construct finite-degree quantum LDPC codes reaching the Gilbert-Varshamov bound from Hsu-Anastasopoulos codes and MacKay-Neal codes. This is a strong distance-theoretic result, but it does not automatically provide practically sparse syndrome measurement or good BP-decoding behavior. In particular, it remains unclear how to turn this into code families that simultaneously retain finite degree, strong distance, implementability, and decoding tractability. In this context, we are particularly interested in the following two open problems.
In other words, the central question is whether the GV-bound-reaching property can be preserved while moving toward code families that are also favorable from the measurement and decoding viewpoints.
Another open problem is to propose qLDPC code ensembles that are genuinely constructible and whose BP decoding performance can be predicted by density evolution.
In arXiv:2511.04634, we attempted to randomize qLDPC constructions, but could not maintain large girth. Meanwhile, the (3,*)-regular constructions studied this year sometimes come experimentally close to DE benchmarks, yet there is still no ensemble-level theory that predicts such behavior in a general constructible setting. Therefore, there is still no fully satisfactory framework that simultaneously supports practical finite-length constructions and analytically tractable ensemble-level performance prediction, so establishing a model that naturally connects code construction and decoding analysis remains open.
A new preprint, joint work with Koki Okada, "A Two-Branch Finite-Field Construction for Regular CSS LDPC Bases", is now available on arXiv.
The construction reduces regularity, CSS orthogonality, and same-type 4-cycle exclusion to finite quotient-coset conditions. The detailed finite-length example uses an \(\mathbb F_{16}\) \((3,10)\)-regular base and a 64-fold CPM lift to obtain a \([[10240,4108,10\le d\le32]]\) CSS code.
For this \([[10240,4108,10\le d\le32]]\) code, the 64-fold lift checks, distance witnesses, and the FER figure are collected on the construction data page.
The slides and read-aloud script for my Boston research visit are now available. The visit took place from May 11 to May 15, 2026. During this stay, I visited QuEra, Harvard, and MIT for research talks and discussions. The talk presents recent work on bringing classical LDPC design principles to quantum LDPC codes under CSS constraints.
📄 Download Slides (Boston Research Visit, 2026)
📄 Download Script (Boston Research Visit, 2026)
A new preprint, joint work with Koki Okada, "High-Girth Regular Quantum LDPC Codes from Affine-Coset Structures", is now available on arXiv.
The paper studies a P=32 CPM-lifted [[16384,4142,≤40]] quantum LDPC code constructed from a girth-8 (3,8)-regular CSS base code. With BP decoding and post-processing, we observed FER about 10-8 at p=0.085.
The decoder, P=32 check matrices, and one-trial iteration tracing example are available on GitHub. The lift coefficients, MatrixMarket \(H_X,H_Z\) files, and FER figure are also collected on the construction data page.
A new preprint, "Heuristic Search for Minimum-Distance Upper-Bound Witnesses in Quantum APM-LDPC Codes", is now available on arXiv.
This work studies certified upper bounds on the minimum distance of quantum APM-LDPC codes constructed from affine permutation matrices. It develops a unified framework for finding low-weight non-stabilizer logical representatives using latent row relations, restricted-lift subspaces, CRT-stripe constructions, cycle-8 trapping-set structures, and decoder-failure residuals.
Candidate witnesses are accepted only after explicit kernel-membership and row-space exclusion tests, so the reported values provide certified upper bounds within the explored parameter range.
A new preprint, "Cross-Commuting Nonabelian Squares in Affine Groups over Finite Commutative Principal Ideal Rings", is now available on arXiv.
The paper studies when two affine families can commute across the two families while each family remains internally noncommutative. For finite commutative principal ideal rings, it gives a complete classification in terms of the local factor decomposition of the ring.
For residue rings, the result yields an exact criterion for when this cross-commuting nonabelian pattern exists in
AGL_1(Z/nZ). The work is also related to the algebraic structure underlying affine-permutation-based quantum code constructions.
Prof. Kenta Kasai has accepted an invitation to deliver an invited talk at the 2026 YITP Fault-Tolerant Logical Processing Workshop, to be held September 28–October 9, 2026 at the Yukawa Institute for Theoretical Physics, Kyoto University (Kyoto, Japan).
The slides and manuscript for ITA 2026 are now available.
📄 Download Slides (ITA 2026)
📄 Download Manuscript (ITA 2026)
Prof. Kenta Kasai has accepted an invitation to serve on the Program Committee for the 8th International Conference on Quantum Error Correction (QEC26), to be held June 7–12, 2026 in Santa Barbara, CA.
We have released a new preprint titled "Breaking the Orthogonality Barrier in Quantum LDPC Codes" on arXiv.
The paper focuses on the orthogonality barrier in quantum LDPC codes and presents a framework and constructions that overcome this constraint.
The paper titled "Quantum error correction near the coding theoretical bound", authored by Daiki Komoto and Kenta Kasai (Institute of Science Tokyo), has been published in npj Quantum Information.
This study proposes a new quantum error correction framework based on LDPC codes that achieves performance near the coding-theoretical (hashing) bound. The work demonstrates efficient decoding for hundreds of thousands of logical qubits, marking a major step toward scalable fault-tolerant quantum computation.
We have released a new preprint titled "Sharp Error-Rate Transitions in Quantum QC-LDPC Codes under Joint BP Decoding" on arXiv.
This work reports the first observation of steep error-rate “waterfall” transitions in quantum LDPC codes with non-vanishing coding rate using binary joint belief propagation decoding. This phenomenon was previously believed to require more complex decoding strategies.
The paper also investigates the cause of error floors, identifying trapping sets in the Tanner graph as key contributors. These insights enable the potential design of codes and decoders that both maintain steep thresholds and reduce the error floor, moving quantum error correction closer to practical deployment.
Our new preprint titled "Quantum Error Correction Exploiting Degeneracy to Approach the Hashing Bound" is now available on arXiv.
This work presents a decoding algorithm that explicitly exploits the degeneracy of quantum errors under the depolarizing channel. Using non-binary LDPC codes and syndrome-based methods, the proposed decoder achieves a frame error rate of $10^{-4}$ at a physical error rate of 9.45% with a code of 104,000 logical qubits and 312,000 physical qubits, approaching the quantum hashing bound.
The following paper and poster presentations have been accepted to ISTC 2025 (13th International Symposium on Topics in Coding), which will be held in Los Angeles, USA, in August 2025.
The regular paper presents a novel construction of quantum APM-LDPC codes using non-circulant affine permutation matrices, demonstrating the feasibility of girth-16 code design beyond the conventional constraints of quantum QC-LDPC codes. The poster presentations provide an overview of recent developments in quantum error correction using non-binary LDPC codes and future directions for high-girth code constructions.
Prof. Kenta Kasai will present his poster titled “Perspectives on Degeneracy and Structure in Non-Binary LDPC Code-Based QEC” at the ISIT 2025 workshop “Quantum Information – Open Problems, Impact, and Challenges (Q-PIC)”.
The workshop focuses on key challenges and open problems in quantum information science, and the poster highlights new perspectives on degeneracy and structural properties in quantum error correction based on non-binary LDPC codes.
The poster will be on display starting at 9:30 AM on June 24, 2025 (Tuesday) at the Rackham Graduate School, University of Michigan. Prof. Kasai will also deliver a 30-second pitch talk and be available for Q&A sessions.
For more details, please visit the Q-PIC workshop page.
Prof. Kenta Kasai will present his recent work titled “Follow-Up Study on Efficient Mitigation of Error Floors in Quantum Error Correction using Non-Binary LDPC Codes” at the Recent Results Poster Session of the IEEE International Symposium on Information Theory (ISIT) 2025.
The session will take place on Monday, June 23, 2025, from 14:30 to 15:50 at the ballroom of the Michigan League in Ann Arbor.
This follow-up study builds upon previously proposed techniques to mitigate error floors in quantum LDPC codes and evaluates their performance and practicality in greater depth.
The poster "Towards Practical Quantum Error Correction: Near-Optimal Performance and Floor Mitigation via Non-Binary LDPC Codes", authored by Kenta Kasai, has been accepted for presentation at the Quantum Error Correction (QEC25) conference.
This work addresses the suppression of error floors in quantum LDPC codes and demonstrates near-optimal performance using non-binary belief propagation decoding.
The acceptance rate for this year’s poster session was below 40%, making it a highly competitive venue for recent results in quantum error correction.
More details available on the QEC25 website.
The paper "Efficient Mitigation of Error Floors in Quantum Error Correction using Non-Binary Low-Density Parity-Check Codes", authored by Kenta Kasai, has been accepted for presentation at the IEEE International Symposium on Information Theory (ISIT 2025).
This paper presents decoding algorithms designed to mitigate the error floor in quantum LDPC codes constructed over non-binary fields, achieving performance close to the hashing bound under practical quantum noise models.
As a follow-up to this work, we will present new results in the Recent Results Poster Session at ISIT 2025, to be held in Ann Arbor, Michigan.
Preprint available on arXiv.
We welcome donations to support our educational and research activities. This program allows corporations, organizations, and individuals to make a donation to Science Tokyo with a designated faculty member as the project coordinator. Donations are used to promote education and research and are shared with society through achievements.
Tax incentives are available for donors. Please refer to the university's guidance for details.
How to apply / details: Donations for Education and Research
University contact: Management Group, Industrial Cooperation Division, Research Promotion Department,
Institute of Science Tokyo
E3-11, 2-12-1, Ookayama, Meguro-ku, Tokyo 152-8550
Tel: 03-5734-3816, Fax: 03-5734-2482
Mail: don.gra[at]cim.isct.ac.jp (replace [at] with @)
If my work aligns with your interests, please feel free to invite me to an online seminar or a casual online meeting. I’m happy to adjust for time zones and can join at any time except 4:00–7:00 a.m. JST.
Email: kenta@ict.eng.isct.ac.jp
Office: Room 418, South Building 3, Ookayama Campus, Institute of Science Tokyo
2-12-1, Ookayama, Meguro-ku, Tokyo 152-8550, Japan

































